bio request request_queue 三者的关系
[!NOTE] 参考 Deepseeek ,有待验证 实话实说,总结的很好:
bio (Block I/O) 是块设备I/O的基本容器。当内核的上层(如文件系统、虚拟内存/交换系统、LVM等)需要读写数据时,它们不关心磁盘的物理特性或如何优化性能,它们只关心一件事: “我需要把这些内存页(pages)的数据,写入到这个块设备的这个逻辑扇区(sector)上,长度是多少。”
在 blk-mq 框架下,I/O的路径发生了变化:
- 直接分发 (Direct Dispatch):当一个 bio 被提交时,blk-mq 会尝试将其直接映射到一个硬件队列上,绕过传统的I/O调度器。
- 调度器可选:blk-mq 仍然可以挂载调度器(如 mq-deadline, kyber),但也可以配置为无调度器 (none)。在这种模式下,bio 会被尽可能快地直接发送到设备驱动。
- request 结构体仍然存在:即使在直接分发的路径中,bio 通常还是会被封装进一个 request 结构体中。但此时的 request 更多地是作为一个通用的“命令容器”,而不是作为调度和合并的对象。它承载着命令的状态、完成信息等,但它跳过了复杂的排序和合并逻辑。
Request queues keep track of outstanding block I/O requests.
Request queues also implement a plug-in interface that allows the use of multiple I/O schedulers (or elevators) to be used.
TODO
- bio 机制是如何实现 : 合并请求
- bio 给上下两个层次提供的接口是什么 ?
blk_update_request参数 nbytes,怎么知道是那个 nbytes 返回的?
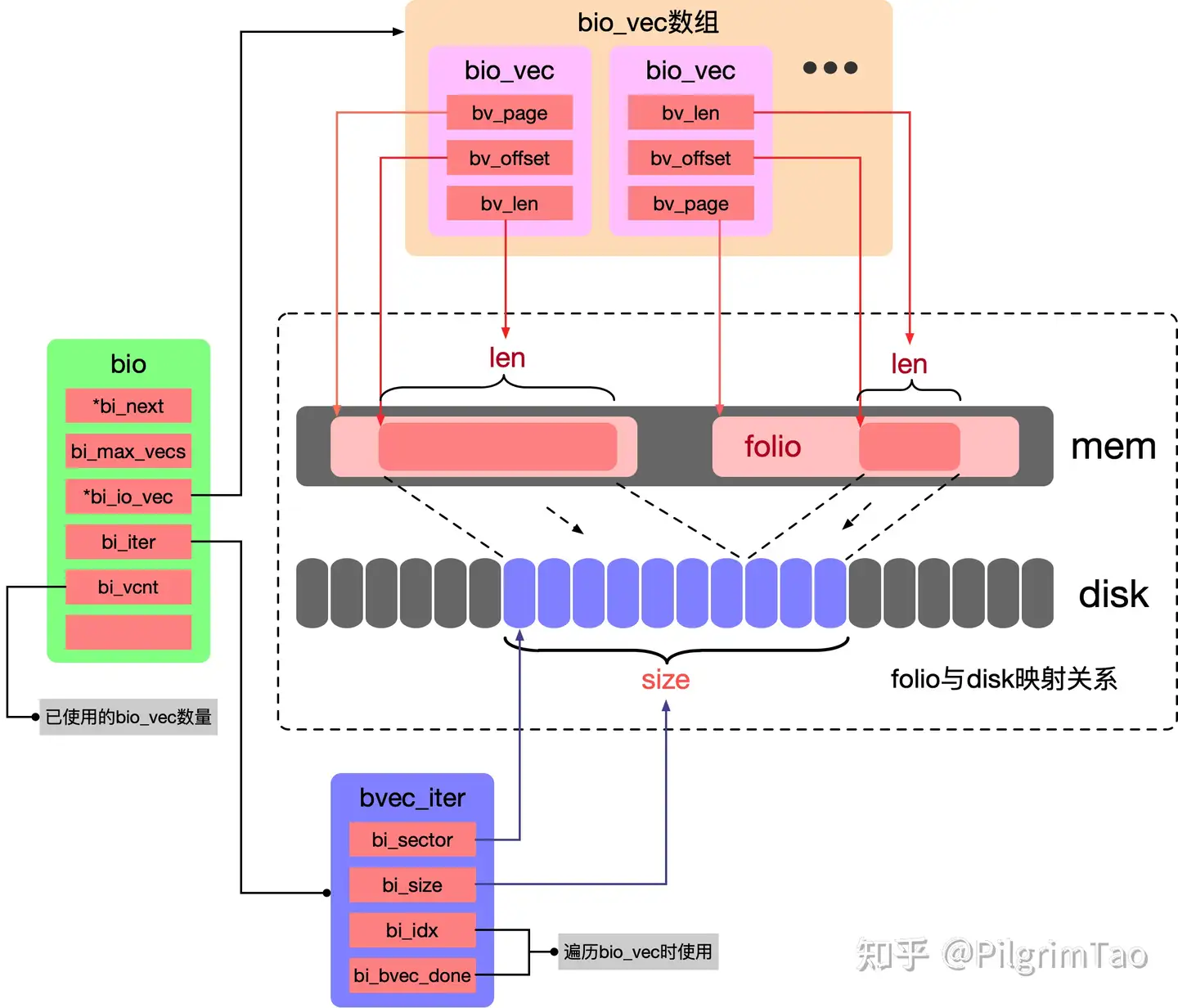
bio bio_vec 和 bio_set 关系是什么?
https://zhuanlan.zhihu.com/p/545906763 中的总结:
| struct | 磁盘物理地址 | 用户文件地址 | 内存物理地址 |
|---|---|---|---|
| bio_vec | 地址连续 | 地址连续 | 地址连续 |
| bio | 地址连续 | 地址连续 | 地址不连续 |
| request | 地址连续 | 地址不连续 | 地址不连续 |
bio request 面对了三个层次,也就是物理内存,文件和物理磁盘
- 物理磁盘必须连续,不然就没有合并的必要了。
- bio_vec 是最简单的,bio 合并多个 bio_vec ,只要文件的地址是连续的
- request 合并多个 bio ,如果物理磁盘是连续的
bio 贴近上层,所以可以知道文件地址的情况,所以其工作是合并连续的文件 而 request 是驱动,知道磁盘布局。
bio_set 不是这个体系下讨论的话题,是主要用于 bio 内存分配的,类似 mempool
/**
* struct bio_vec - a contiguous range of physical memory addresses
* @bv_page: First page associated with the address range.
* @bv_len: Number of bytes in the address range.
* @bv_offset: Start of the address range relative to the start of @bv_page.
*
* The following holds for a bvec if n * PAGE_SIZE < bv_offset + bv_len:
*
* nth_page(@bv_page, n) == @bv_page + n
*
* This holds because page_is_mergeable() checks the above property.
*/
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
继续思考的问题:
- 一个 page 比一个 block 更大,导致一个 page 可能映射到多个不连续的 disk block 中。
- 从 iovec 到 bio 的转换过程是什么样子的
- 似乎是,只有知道了 page 映射到哪一个 disk ,才能生成 bio
- 那么元数据的代码产生的 bio 大致是什么样子的
request 容易理解,如果多个 bio 对应的 disk 地址连续,那么将他们都加进来。
__blkdev_direct_IO 中,分配的 bio vector 的数量正好是 nr_pages 的数量:
bio = bio_alloc(bdev, nr_pages, opf, GFP_KERNEL);
似乎需要首先理解 iomap 和 buffer head 才可以
submit_bio
- 这是 fs 和 dev 进行 io 的唯一的接口吗 ?
- submit_bio 和 generic_make_request 的关系是什么 ? 两者都是类似接口,但是 submit_bio 做出部分检查,最后调用 generic_make_request
iomap 直接来调用 submit_bio,有趣
bio
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
blk_opf_t bi_opf; /* bottom bits REQ_OP, top bits
* req_flags.
*/
unsigned short bi_flags; /* BIO_* below */
unsigned short bi_ioprio;
blk_status_t bi_status;
atomic_t __bi_remaining;
struct bvec_iter bi_iter;
blk_qc_t bi_cookie;
bio_end_io_t *bi_end_io;
void *bi_private;
#ifdef CONFIG_BLK_CGROUP
/*
* Represents the association of the css and request_queue for the bio.
* If a bio goes direct to device, it will not have a blkg as it will
* not have a request_queue associated with it. The reference is put
* on release of the bio.
*/
struct blkcg_gq *bi_blkg;
struct bio_issue bi_issue;
#ifdef CONFIG_BLK_CGROUP_IOCOST
u64 bi_iocost_cost;
#endif
#endif
#ifdef CONFIG_BLK_INLINE_ENCRYPTION
struct bio_crypt_ctx *bi_crypt_context;
#endif
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
};
unsigned short bi_vcnt; /* how many bio_vec's */
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[];
};
[ ] bio:bi_opf
enum req_flag_bits {
__REQ_FAILFAST_DEV = /* no driver retries of device errors */
REQ_OP_BITS,
__REQ_FAILFAST_TRANSPORT, /* no driver retries of transport errors */
__REQ_FAILFAST_DRIVER, /* no driver retries of driver errors */
__REQ_SYNC, /* request is sync (sync write or read) */
__REQ_META, /* metadata io request */
__REQ_PRIO, /* boost priority in cfq */
__REQ_NOMERGE, /* don't touch this for merging */
__REQ_IDLE, /* anticipate more IO after this one */
__REQ_INTEGRITY, /* I/O includes block integrity payload */
__REQ_FUA, /* forced unit access */
__REQ_PREFLUSH, /* request for cache flush */
__REQ_RAHEAD, /* read ahead, can fail anytime */
__REQ_BACKGROUND, /* background IO */
__REQ_NOWAIT, /* Don't wait if request will block */
/*
* When a shared kthread needs to issue a bio for a cgroup, doing
* so synchronously can lead to priority inversions as the kthread
* can be trapped waiting for that cgroup. CGROUP_PUNT flag makes
* submit_bio() punt the actual issuing to a dedicated per-blkcg
* work item to avoid such priority inversions.
*/
__REQ_CGROUP_PUNT,
__REQ_POLLED, /* caller polls for completion using bio_poll */
__REQ_ALLOC_CACHE, /* allocate IO from cache if available */
__REQ_SWAP, /* swap I/O */
__REQ_DRV, /* for driver use */
/*
* Command specific flags, keep last:
*/
/* for REQ_OP_WRITE_ZEROES: */
__REQ_NOUNMAP, /* do not free blocks when zeroing */
__REQ_NR_BITS, /* stops here */
};
bio::bio_vec
/**
* struct bio_vec - a contiguous range of physical memory addresses
* @bv_page: First page associated with the address range.
* @bv_len: Number of bytes in the address range.
* @bv_offset: Start of the address range relative to the start of @bv_page.
*
* The following holds for a bvec if n * PAGE_SIZE < bv_offset + bv_len:
*
* nth_page(@bv_page, n) == @bv_page + n
*
* This holds because page_is_mergeable() checks the above property.
*/
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
确实就是图上的样子。
bio::bi_iter
在一个静态环境中的时间:
@[
bio_alloc_bioset+5
ext4_mpage_readpages+1100
read_pages+88
page_cache_ra_unbounded+315
filemap_fault+1459
__do_fault+49
do_fault+435
__handle_mm_fault+1581
handle_mm_fault+259
do_user_addr_fault+464
exc_page_fault+107
asm_exc_page_fault+38
]: 2742
- ext4_mpage_readpages
- bio = bio_alloc(bdev, bio_max_segs(nr_pages), REQ_OP_READ, GFP_KERNEL);
- ext4_bio_write_page
- io_submit_add_bh
- io_submit_init_bio
- bio = bio_alloc(bh->b_bdev, BIO_MAX_VECS, REQ_OP_WRITE, GFP_NOIO);
- io_submit_init_bio
- io_submit_add_bh
- bio_alloc :
bio_alloc_biosetbvec_alloc
bioset_init: 使用 pool 处理 bio 的分配问题
struct bvec_iter {
sector_t bi_sector; /* device address in 512 byte
sectors */
unsigned int bi_size; /* residual I/O count */
unsigned int bi_idx; /* current index into bvl_vec */
unsigned int bi_bvec_done; /* number of bytes completed in
current bvec */
} __packed;
似乎是 bi_idx 和 bi_bvec_done 的确是记录提交的顺序的,但是没有绝对的证据
好奇怪,
#0 bvec_iter_advance (bytes=1310720, iter=0xffff88810d641f20, bv=0xffff888105bb3000) at ./include/linux/bvec.h:143
#1 bio_advance_iter (bytes=1310720, iter=0xffff88810d641f20, bio=0xffff88810d641f00) at ./include/linux/bio.h:106
#2 __bio_advance (bio=bio@entry=0xffff88810d641f00, bytes=bytes@entry=1310720) at block/bio.c:1392
#3 0xffffffff81739441 in bio_advance (nbytes=<optimized out>, bio=0xffff88810d641f00) at ./include/linux/bio.h:142
#4 bio_split (bio=bio@entry=0xffff88810d641f00, sectors=<optimized out>, gfp=gfp@entry=3072, bs=bs@entry=0xffffffff81738fa4 <bio_alloc_bioset+628>) at block/bio.c:1646
#5 0xffffffff8174505f in bio_split_rw (bio=bio@entry=0xffff88810d641f00, lim=<optimized out>, segs=0xffff88810d641f00, segs@entry=0xffffc90001c87804, bs=0xffffffff81738fa4 <bio_alloc_bioset+628>, max_bytes=<optimized out>) at block/blk-merge.c:337
#6 0xffffffff81745a45 in __bio_split_to_limits (bio=bio@entry=0xffff88810d641f00, lim=lim@entry=0xffff888107591e08, nr_segs=nr_segs@entry=0xffffc90001c87804) at block/blk-mer ge.c:370
#7 0xffffffff8174e863 in blk_mq_submit_bio (bio=0xffff88810d641f00) at block/blk-mq.c:2943
#8 0xffffffff8173e817 in __submit_bio (bio=bio@entry=0xffff88810d641f00) at block/blk-core.c:602
#9 0xffffffff8173ee92 in __submit_bio_noacct_mq (bio=0xffff88810d641f00) at block/blk-core.c:679
#10 submit_bio_noacct_nocheck (bio=<optimized out>) at block/blk-core.c:708
#11 0xffffffff8173f060 in submit_bio_noacct (bio=<optimized out>) at block/blk-core.c:807
#12 0xffffffff81526f0e in ext4_mpage_readpages (inode=<optimized out>, rac=<optimized out>, page=<optimized out>) at fs/ext4/readpage.c:402
#13 0xffffffff8133f428 in read_pages (rac=rac@entry=0xffffc90001c87ab0) at mm/readahead.c:161
#14 0xffffffff8133f73b in page_cache_ra_unbounded (ractl=ractl@entry=0xffffc90001c87ab0, nr_to_read=513, lookahead_size=<optimized out>) at mm/readahead.c:270
#15 0xffffffff8133fd00 in do_page_cache_ra (lookahead_size=<optimized out>, nr_to_read=<optimized out>, ractl=0xffffc90001c87ab0) at mm/readahead.c:300
#16 0xffffffff81332d24 in do_sync_mmap_readahead (vmf=0xffffc90001c87b98) at mm/filemap.c:3190
#17 filemap_fault (vmf=0xffffc90001c87b98) at mm/filemap.c:3282
#18 0xffffffff81374d61 in __do_fault (vmf=vmf@entry=0xffffc90001c87b98) at mm/memory.c:4155
#19 0xffffffff81379505 in do_cow_fault (vmf=0xffffc90001c87b98) at mm/memory.c:4536
#20 do_fault (vmf=vmf@entry=0xffffc90001c87b98) at mm/memory.c:4637
#21 0xffffffff8137e1df in handle_pte_fault (vmf=0xffffc90001c87b98) at mm/memory.c:4923
#22 __handle_mm_fault (vma=vma@entry=0xffff88810611d688, address=address@entry=94523413734384, flags=flags@entry=533) at mm/memory.c:5065
#23 0xffffffff8137eeea in handle_mm_fault (vma=0xffff88810611d688, address=address@entry=94523413734384, flags=<optimized out>, flags@entry=533, regs=regs@entry=0xffffc90001c87cf8) at mm/memory.c:5211
#24 0xffffffff811211f6 in do_user_addr_fault (regs=0xffffc90001c87cf8, error_code=2, address=94523413734384) at arch/x86/mm/fault.c:1407
#25 0xffffffff82293c80 in handle_page_fault (address=94523413734384, error_code=2, regs=0xffffc90001c87cf8) at arch/x86/mm/fault.c:1498
#26 exc_page_fault (regs=0xffffc90001c87cf8, error_code=2) at arch/x86/mm/fault.c:1554
#27 0xffffffff82401286 in asm_exc_page_fault () at ./arch/x86/include/asm/idtentry.h:570
这个是证据,在
- req_bio_endio
- bio_advance
- bio_endio
#0 req_bio_endio (error=0 '\000', nbytes=4096, bio=0xffff88810cbd6000, rq=0xffff8881099e6480) at block/blk-mq.c:789
#1 blk_update_request (req=req@entry=0xffff8881099e6480, error=error@entry=0 '\000', nr_bytes=4096) at block/blk-mq.c:927
#2 0xffffffff8174c29e in blk_mq_end_request (rq=rq@entry=0xffff8881099e6480, error=error@entry=0 '\000') at block/blk-mq.c:1054
#3 0xffffffff81b72c6a in virtblk_request_done (req=0xffff8881099e6480) at drivers/block/virtio_blk.c:348
#4 virtblk_handle_req (vq=vq@entry=0xffff8881095fc180, iob=iob@entry=0xffffc900002e0ef8) at drivers/block/virtio_blk.c:376
#5 0xffffffff81b72d9f in virtblk_done (vq=0xffff888107860200) at drivers/block/virtio_blk.c:394
#6 0xffffffff818b39ab in vring_interrupt (irq=<optimized out>, _vq=0x1 <fixed_percpu_data+1>) at drivers/virtio/virtio_ring.c:2491
#7 vring_interrupt (irq=<optimized out>, _vq=0x1 <fixed_percpu_data+1>) at drivers/virtio/virtio_ring.c:2466
#8 0xffffffff811c926d in __handle_irq_event_percpu (desc=desc@entry=0xffff888109678000) at kernel/irq/handle.c:158
#9 0xffffffff811c9478 in handle_irq_event_percpu (desc=0xffff888109678000) at kernel/irq/handle.c:193
#10 handle_irq_event (desc=desc@entry=0xffff888109678000) at kernel/irq/handle.c:210
#11 0xffffffff811ce39b in handle_edge_irq (desc=0xffff888109678000) at kernel/irq/chip.c:819
#12 0xffffffff810d9d9f in generic_handle_irq_desc (desc=0xffff888109678000) at ./include/linux/irqdesc.h:158
#13 handle_irq (regs=<optimized out>, desc=0xffff888109678000) at arch/x86/kernel/irq.c:231
#14 __common_interrupt (regs=<optimized out>, vector=8) at arch/x86/kernel/irq.c:250
#15 0xffffffff82290e7f in common_interrupt (regs=0xffffc900000d7e38, error_code=<optimized out>) at arch/x86/kernel/irq.c:240
而且从 raid1 中使用的 bio_split 也可以发现 bio 的返回就是做左向右的。
bio::bi_end_io
submit_bio 是异步的,但是可以修改为同步的,通过设置 bio::bi_end_io 来提醒结束,否则始终等待在 上面。
#0 io_schedule_timeout (timeout=timeout@entry=9223372036854775807) at kernel/sched/core.c:8794
#1 0xffffffff821906a3 in do_wait_for_common (state=2, timeout=9223372036854775807, action=0xffffffff8218ea70 <io_schedule_timeout>, x=0xffffc9003f94fe20) at kernel/sched/build_utility.c:3653
#2 __wait_for_common (x=x@entry=0xffffc9003f94fe20, action=0xffffffff8218ea70 <io_schedule_timeout>, timeout=timeout@entry=9223372036854775807, state=state@entry=2) at kernel/sched/build_utility.c:3674
#3 0xffffffff8219099f in wait_for_common_io (state=2, timeout=9223372036854775807, x=0xffffc9003f94fe20) at kernel/sched/build_utility.c:3691
#4 0xffffffff816ba46a in submit_bio_wait (bio=bio@entry=0xffffc9003f94fe58) at block/bio.c:1388
#5 0xffffffff816c408b in blkdev_issue_flush (bdev=<optimized out>) at block/blk-flush.c:467
#6 0xffffffff8148bf39 in ext4_sync_file (file=0xffff888145091e00, start=<optimized out>, end=<optimized out>, datasync=<optimized out>) at fs/ext4/fsync.c:177
#7 0xffffffff8140af15 in vfs_fsync_range (datasync=1, end=9223372036854775807, start=0, file=0xffff888145091e00) at fs/sync.c:188
#8 vfs_fsync (datasync=1, file=0xffff888145091e00) at fs/sync.c:202
#9 do_fsync (datasync=1, fd=<optimized out>) at fs/sync.c:212
#10 __do_sys_fdatasync (fd=<optimized out>) at fs/sync.c:225
#11 __se_sys_fdatasync (fd=<optimized out>) at fs/sync.c:223
#12 __x64_sys_fdatasync (regs=<optimized out>) at fs/sync.c:223
#13 0xffffffff82180c3f in do_syscall_x64 (nr=<optimized out>, regs=0xffffc9003f94ff58) at arch/x86/entry/common.c:50
#14 do_syscall_64 (regs=0xffffc9003f94ff58, nr=<optimized out>) at arch/x86/entry/common.c:80
#15 0xffffffff822000ae in entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
通知 bio 结束的执行流程:
#0 bio_endio (bio=bio@entry=0xffff888104430100) at block/bio.c:1577
#1 0xffffffff816cd00c in req_bio_endio (error=0 '\000', nbytes=4096, bio=0xffff888104430100, rq=0xffff8881042d1680) at block/blk-mq.c:794
#2 blk_update_request (req=req@entry=0xffff8881042d1680, error=error@entry=0 '\000', nr_bytes=4096) at block/blk-mq.c:926
#3 0xffffffff816cd349 in blk_mq_end_request (rq=0xffff8881042d1680, error=0 '\000') at block/blk-mq.c:1053
#4 0xffffffff81aa9e99 in virtblk_done (vq=0xffff8881008a7000) at drivers/block/virtio_blk.c:291
#5 0xffffffff818134f9 in vring_interrupt (irq=<optimized out>, _vq=<optimized out>) at drivers/virtio/virtio_ring.c:2470
#6 vring_interrupt (irq=<optimized out>, _vq=<optimized out>) at drivers/virtio/virtio_ring.c:2445
#7 0xffffffff811a3d35 in __handle_irq_event_percpu (desc=desc@entry=0xffff888100cb7a00) at kernel/irq/handle.c:158
#8 0xffffffff811a3f13 in handle_irq_event_percpu (desc=0xffff888100cb7a00) at kernel/irq/handle.c:193
#9 handle_irq_event (desc=desc@entry=0xffff888100cb7a00) at kernel/irq/handle.c:210
#10 0xffffffff811a8bee in handle_edge_irq (desc=0xffff888100cb7a00) at kernel/irq/chip.c:819
#11 0xffffffff810ce1d8 in generic_handle_irq_desc (desc=0xffff888100cb7a00) at ./include/linux/irqdesc.h:158
#12 handle_irq (regs=<optimized out>, desc=0xffff888100cb7a00) at arch/x86/kernel/irq.c:231
#13 __common_interrupt (regs=<optimized out>, vector=35) at arch/x86/kernel/irq.c:250
#14 0xffffffff8218a897 in common_interrupt (regs=0xffffc900000a3e38, error_code=<optimized out>) at arch/x86/kernel/irq.c:240
几乎每一个和 bio 打交道的都会对应的注册 bio::bi_end_io
request
/*
* The hash is used inside the scheduler, and killed once the
* request reaches the dispatch list. The ipi_list is only used
* to queue the request for softirq completion, which is long
* after the request has been unhashed (and even removed from
* the dispatch list).
*/
union {
struct hlist_node hash; /* merge hash */
struct llist_node ipi_list;
};
ipi_list的使用大致知道了,但是hash如何操作来着?
task_struct::bio_list
/*
* The loop in this function may be a bit non-obvious, and so deserves some
* explanation:
*
* - Before entering the loop, bio->bi_next is NULL (as all callers ensure
* that), so we have a list with a single bio.
* - We pretend that we have just taken it off a longer list, so we assign
* bio_list to a pointer to the bio_list_on_stack, thus initialising the
* bio_list of new bios to be added. ->submit_bio() may indeed add some more
* bios through a recursive call to submit_bio_noacct. If it did, we find a
* non-NULL value in bio_list and re-enter the loop from the top.
* - In this case we really did just take the bio of the top of the list (no
* pretending) and so remove it from bio_list, and call into ->submit_bio()
* again.
*
* bio_list_on_stack[0] contains bios submitted by the current ->submit_bio.
* bio_list_on_stack[1] contains bios that were submitted before the current
* ->submit_bio, but that haven't been processed yet.
*/
static void __submit_bio_noacct(struct bio *bio)
{
struct bio_list bio_list_on_stack[2];
- submit_bio_noacct
- submit_bio_noacct_nocheck
- bio_list_add(¤t->bio_list[0], bio);
__submit_bio_noacct_mq: 普通的 io 一般走这个路径,有点类似简化版本的__submit_bio_noacct__submit_bio_noacct: md dm 之类的走这个路径- current->bio_list = bio_list_on_stack;
__submit_bio: 循环调用- blk_mq_submit_bio
- current->bio_list = NULL;
- submit_bio_noacct_nocheck
正如 submit_bio_noacct_nocheck 中间的注释所说,这个是为了处理 ->submit_bio 的递归调用的。
关键参考
- A block layer introduction part 1: the bio layer
- Block layer introduction part 2: the request layer
- Linux IO 请求处理流程-bio 和 request
- IO 子系统全流程介绍
以 mddev::queue 到 mddev::gendisk::queue 的转变
之前的时候 mddev 中引用了 request_queue ,但是后来移除掉了
struct mddev {
struct request_queue *queue; /* for plugging ... */
commit 396799eb5b6f (“md: remove mddev->queue”) commit 176df894d797 (“md: add a mddev_is_dm helper”)
后来直接变为使用 mddev::gendisk
/*
* MD devices can be used undeneath by DM, in which case ->gendisk is NULL.
*/
static inline bool mddev_is_dm(struct mddev *mddev)
{
return !mddev->gendisk;
}
gendisk::queue
首先,gendisk 是对应一个盘,而不是一个分区的。
struct gendisk {
/*
* major/first_minor/minors should not be set by any new driver, the
* block core will take care of allocating them automatically.
*/
int major;
int first_minor;
int minors;
// ...
}
正如我们常说的,一个盘对应一个 request_queue
热插一个 virtio scsi disk 的结果:
当 scsi_alloc_sdev 的时候,通过 blk_mq_alloc_queue 从 tag_set 哪里分配一个 mq ,最后提供给 __alloc_disk_node
@[
__alloc_disk_node+5
blk_mq_alloc_disk_for_queue+51
sd_probe+173
really_probe+219
__driver_probe_device+120
driver_probe_device+31
__device_attach_driver+137
bus_for_each_drv+144
__device_attach_async_helper+163
async_run_entry_fn+49
process_one_work+368
worker_thread+597
kthread+236
ret_from_fork+49
ret_from_fork_asm+26
]: 1
mddev::gendisk 的意义
md_alloc 中看到
disk = blk_alloc_disk(NULL, NUMA_NO_NODE);
这个 gendisk 就是我们看到的 /dev/md127
raid5_unplug 中
if (mddev->queue)
trace_block_unplug(mddev->queue, cnt, !from_schedule);
static void mddev_detach(struct mddev *mddev)
{
mddev->bitmap_ops->wait_behind_writes(mddev);
if (mddev->pers && mddev->pers->quiesce && !is_md_suspended(mddev)) {
mddev->pers->quiesce(mddev, 1);
mddev->pers->quiesce(mddev, 0);
}
md_unregister_thread(mddev, &mddev->thread);
/* the unplug fn references 'conf' */
if (!mddev_is_dm(mddev))
blk_sync_queue(mddev->gendisk->queue);
}
虽然 gendisk 中存在其对应的 request_queue ,但是 应该不在于提交 io ,而是一些通用机制了。
bio_add_folio
- entry_SYSCALL_64
- do_syscall_64
- do_syscall_x64
- ksys_read
- vfs_read
- new_sync_read
- call_read_iter
- blkdev_read_iter
- filemap_read
- filemap_get_pages
- page_cache_sync_readahead
- page_cache_sync_ra
- force_page_cache_ra
- do_page_cache_ra
- page_cache_ra_unbounded
- read_pages
- mpage_readahead
- do_mpage_readpage
- bio_add_folio
- do_mpage_readpage
- mpage_readahead
- read_pages
- page_cache_ra_unbounded
- do_page_cache_ra
- force_page_cache_ra
- page_cache_sync_ra
- page_cache_sync_readahead
- filemap_get_pages
- filemap_read
- blkdev_read_iter
- call_read_iter
- new_sync_read
- vfs_read
- ksys_read
- do_syscall_x64
- do_syscall_64
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。