workqueue
workqueue 就是最经典的,还不会用,就开始看原理了。
文件看上去有很多,实际上一半是注释,很多是 sysfs 的接口,其实强度还行
- http://127.0.0.1:3434/core-api/workqueue.html
TODO
- 找到 worker 如何通过 workqueue_struct 到达 worker_pool 的 ?
- 任务工厂 - Linux 中的 workqueue 机制 [一]
- 一个 CPU 上同一优先级的所有 worker 线程(优先级的概念见下文)共同构成了一个 worker pool(此概念由内核 v3.8 引入)
- 任务工厂 - Linux 中的 workqueue 机制 [二]
- Linux - workqueue 的三种延迟
才意识到,在一个 worker thread 上睡眠,那么该 worker thread 就相当于报废了,这个 worker thread 无法处理其他的 work 了, 此时正确的处理办法是让另一个 worker thread 来处理事情。
-
kworker 的命名是怎么回事来着?
-
workqueue 的 delay 和非 delay 应该还是存在重要的思考,不然为什么各种接口都要写两套?
- 例如 flush_work 和 flush_delayed_work 之类的
color 是什么意思
- https://lore.kernel.org/patchwork/patch/204822/
- 用于 flush work 的
sysfs 接口
/sys/devices/virtual/workqueue/writeback
和想想不同,实际上内容并不多
Permissions Size User Date Modified Name
drwxr-xr-x - root 20 Sep 20:51 blkcg_punt_bio
.rw-r--r-- 4.1k root 20 Sep 20:51 cpumask
drwxr-xr-x - root 20 Sep 20:51 nvme-delete-wq
drwxr-xr-x - root 20 Sep 20:51 nvme-reset-wq
drwxr-xr-x - root 20 Sep 20:51 nvme-wq
drwxr-xr-x - root 20 Sep 20:51 power
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_0
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_1
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_2
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_3
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_4
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_5
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_6
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_7
drwxr-xr-x - root 20 Sep 20:51 scsi_tmf_8
.rw-r--r-- 4.1k root 20 Sep 20:51 uevent
drwxr-xr-x - root 20 Sep 20:51 writeback
但是这个一定会初始化,在这个目录也是没有看到的,看来这个目录并不是显示任何东西:
/* Initializes the TDP MMU for the VM, if enabled. */
int kvm_mmu_init_tdp_mmu(struct kvm *kvm)
{
struct workqueue_struct *wq;
wq = alloc_workqueue("kvm", WQ_UNBOUND|WQ_MEM_RECLAIM|WQ_CPU_INTENSIVE, 0);
if (!wq)
return -ENOMEM;
INIT_LIST_HEAD(&kvm->arch.tdp_mmu_roots);
spin_lock_init(&kvm->arch.tdp_mmu_pages_lock);
kvm->arch.tdp_mmu_zap_wq = wq;
return 1;
}
总结
-
内核默认创建了一些工作队列(用户也可以创建) 比如 system_mq system_highpri_mq 这些都是 unbounded
- 不是, system_wq 是 bounded 的,但是 system_unbound_wq 是
-
workqueue 的几个对象 : work, worker, worker_pool, workqueue, pool_workqueue 的创建
- work 完全用户动态创建的
- worker 根据负载决定
- worker_pool 会默认创建一些
- workqueue 的创建会进一步创建 pool_workqueue,可能创建符合其属性的 worker_pool
- 对于 bounded 的,其会关联到 cpu_worker_pools 上
- 对于 unbounded 的, 如果不存在满足该 workqueue 的属性代码,那么就需要创建新的 worker_pool,参考 alloc_unbound_pwq
/* the per-cpu worker pools */
static DEFINE_PER_CPU_SHARED_ALIGNED(struct worker_pool [NR_STD_WORKER_POOLS], cpu_worker_pools);
总体来说,queue_work 将 work 放到 workqueue 上,然后转移到 worker_pool 上,最后被 worker 执行
每个 cpu 创建两个 per_cpu 的 worker_pool. unbounded 和 bounded 的 workqueue 的两个属性
alloc_and_link_pwqs
- init_pwq : 初始化,将自己分别指向 worker_pool 和 workqueue
- link_pwq : 将自己挂载到创建 workqueue 上
一个 workqueue 可以持有多个 pwq, 比如给每一个 cpu 的 worker_pool 分配对应优先级的 workqueue 划分为 bounded 和 unbounded 的属性, 划分优先级
针对非绑定类型的工作队列,worker_pool 创建后会添加到 unbound_pool_hash 哈希表中;
存在 unbounded 的 worker pool 吗?
判断 workqueue 的类型,如果是 bound 类型,根据 CPU 来获取 pool_workqueue,如果是 unbound 类型,通过 node 号来获取 pool_workqueue;
__queue_work- wq_select_unbound_cpu : 如果是 unbounded, 最好是使用当前 cpu
- unbound_pwq_by_node : 否则使用
___queue_work的内容, 这两个函数最终是为了找到 pwq, 实际上为了进一步的获取 worker_pool - get_work_pool : 直接获取到 worker_pool 的内容
- find_worker_executing_work : 如果 work 上一次执行的 worker_pool 和 unbound_pwq_by_node/wq_select_unbound_cpu 得到 pwq 指向的 worker 不是一个东西,那么就要考虑 cache 的问题
- insert_work : 挂到选出来的 worker_pool::worklist 链表上
给定一个 pwq,其唯一定位出来一个 workqueue 和 worker_pool
worker_thread 在开始执行时,设置标志位 PF_WQ_WORKER,调度器在进行调度处理时会对 task 进行判断,针对 workerqueue worker 有特殊处理;
- 在
__schedule和ttwu_active的时候,会对于pool->nr_running进行统计,并且同时辅助 worker 的唤醒,创建等操作
struct work_struct
struct work_struct用来描述work,初始化一个work并添加到工作队列后,将会将其传递到合适的内核线程来进行处理,它是用于调度的最小单位。
struct work_struct {
atomic_long_t data; //低比特存放状态位,高比特存放worker_pool的ID或者pool_workqueue的指针
struct list_head entry; //用于添加到其他队列上
work_func_t func; //工作任务的处理函数,在内核线程中回调
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
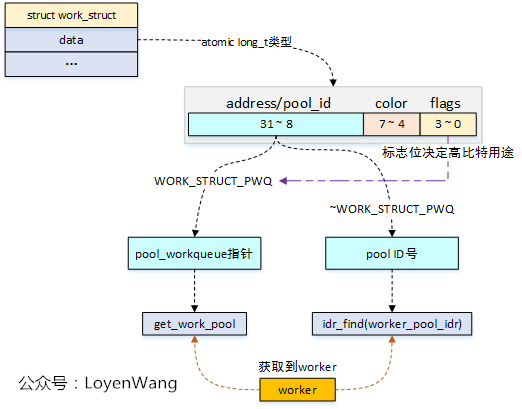
get_work_pool 使用方法:
- 如果 work 关联了 pool_workqueue, 可以找到对应的 pool_workqueue
- 否则找到其曾经使用过的 worker_pool, 当然,如果有的话
flush_work : 利用 barrier work 的方法,一直阻塞,直到目标工作完成了
principal
- 和这个 workqueue 相关的 pool_workqueue 被挂入一个链表,链表头就是 workqueue_struct 中的 pwqs 成员。
wowotech
保持 workqueue 的接口不变,利用 work pool 和 worker thread
用户可以创建 workqueue(不创建 worker pool)并通过 flag 来约束挂入该 workqueue 上 work 的处理方式。 workqueue 会根据其 flag 将 work 交付给系统中某个 worker pool 处理。 例如如果该 workqueue 是 bounded 类型并且设定了 high priority,那么挂入该 workqueue 的 work 将由 per cpu 的 highpri worker-pool 来处理。
由此看来,workqueue 只是简单的前端接口,像是一个入口,之后放到此处的 work 由此导入到具体的 workqueue 中间 但是,workqueue 还会持有一些限制在其中。
在 kernel 中,有两种线程池,一种是线程池是 per cpu 的,也就是说,系统中有多少个 cpu,就会创建多少个线程池,cpu x 上的线程池创建的 worker 线程也只会运行在 cpu x 上。另外一种是 unbound thread pool,该线程池创建的 worker 线程可以调度到任意的 cpu 上去。
cpu x 上创建的,只会在 cpu x 上的 worker pool 上运行,如何实现这一个效果。
和旧的 workqueue 机制一样,系统维护了一个所有 workqueue 的 list,list head 定义如下:
static LIST_HEAD(workqueues); /* PR: list of all workqueues */
挂入 workqueue 的 work 终究是需要 worker 线程来处理,针对 worker 线程有下面几个考量点(我们称之 attribute):
- 该 worker 线程的优先级
- 该 worker 线程运行在哪一个 CPU 上
- 如果 worker 线程可以运行在多个 CPU 上,且这些 CPU 属于不同的 NUMA node,那么是否在所有的 NUMA node 中都可以获取良好的性能。
对于 per-CPU 的 workqueue,2 和 3 不存在问题,哪个 cpu 上 queue 的 work 就在哪个 cpu 上执行,由于只能在一个确定的 cpu 上执行, 因此起 NUMA 的 node 也是确定的(一个 CPU 不可能属于两个 NUMA node)。置于优先级,per-CPU 的 workqueue 使用 WQ_HIGHPRI 来标记。 综上所述,per-CPU 的 workqueue 不需要单独定义一个 workqueue attribute,这也是为何在 workqueue_struct 中只有 unbound_attrs 这个成员来记录 unbound workqueue 的属性。
NUMA 是内存管理的范畴,本文不会深入描述,我们暂且放开 NUMA,先思考这样的一个问题:一个确定属性的 unbound workqueue 需要几个线程池? 看起来一个就够了,毕竟 workqueue 的属性已经确定了,一个线程池创建相同属性的 worker thread 就行了。 但是我们来看一个例子:假设 workqueue 的 work 是可以在 node 0 中的 CPU A 和 B,以及 node 1 中 CPU C 和 D 上处理,如果只有一个 thread pool, 那么就会存在 worker thread 在不同 node 之间的迁移问题。为了解决这个问题,实际上 unbound workqueue 实际上是创建了 per node 的 pool_workqueue(thread pool)
可以细品,总体来说,内容是清晰的
分配 pool workqueue 的内存并建立 workqueue 和 pool workqueue 的关系,这部分的代码主要涉及 alloc_and_link_pwqs 函数
/* content equality test */
static bool wqattrs_equal(const struct workqueue_attrs *a,
const struct workqueue_attrs *b)
{
if (a->nice != b->nice)
return false;
if (!cpumask_equal(a->cpumask, b->cpumask))
return false;
return true;
}
所谓的 wqattrs 就是优先级和可以运行的 cpu 限制, wqattrs 不仅仅描述 workqueue 的属性,还可以描述 worker_pool 的属性. 当创建 workqueue 的时候,如果不存在对应属性的 worker_pool, 在 get_unbound_pool 会动态创建的
workqueue_init 中间对于每一个 cpu 的两个 worker_pool 和 所有的 unbounded 的 workqueue 创建 worker
workqueue.rst
In order to ease the asynchronous execution of functions a new abstraction, the work item, is introduced.
Special purpose threads, called worker threads, execute the functions off of the queue, one after the other. If no work is queued, the worker threads become idle. These worker threads are managed in so called worker-pools.
特殊线程来分别执行这些函数,类似于 syscall 一样吗 ?
For any worker pool implementation, managing the concurrency level (how many execution contexts are active) is an important issue. cmwq tries to keep the concurrency at a minimal but sufficient level. Minimal to save resources and sufficient in that the system is used at its full capacity.
Each worker-pool bound to an actual CPU implements concurrency management by hooking into the scheduler. The worker-pool is notified whenever an active worker wakes up or sleeps and keeps track of the number of the currently runnable workers.
For unbound workqueues, the number of backing pools is dynamic.
Unbound workqueue can be assigned custom attributes using
apply_workqueue_attrs() and workqueue will automatically create
backing worker pools matching the attributes.
misc
1 I root 205 2 0 60 -20 - 0 - Sep20 ? 00:00:00 [kworker/15:0H-events_highpri]
1 I root 251 2 0 80 0 - 0 - Sep20 ? 00:00:00 [kworker/30:1-events]
1 I root 107030 2 0 80 0 - 0 - 09:55 ? 00:00:00 [kworker/0:1-events]
1 I root 107254 2 0 80 0 - 0 - 09:56 ? 00:00:00 [kworker/19:4-events]
1 I root 107606 2 0 80 0 - 0 - 09:56 ? 00:00:00 [kworker/1:0-events]
1 I root 107883 2 0 80 0 - 0 - 09:56 ? 00:00:00 [kworker/1:3-events_power_efficient]
1 I root 108756 2 0 80 0 - 0 - 10:00 ? 00:00:00 [kworker/8:1-events]
1 I root 109079 2 0 80 0 - 0 - 10:02 ? 00:00:00 [kworker/u64:13-events_unbound]
1 I root 109506 2 0 80 0 - 0 - 10:03 ? 00:00:00 [kworker/4:2-events]
1 I root 109974 2 0 80 0 - 0 - 10:06 ? 00:00:00 [kworker/19:0-events]
1 I root 110197 2 0 80 0 - 0 - 10:07 ? 00:00:00 [kworker/10:0-events_freezable_power_]
1 I root 110301 2 0 80 0 - 0 - 10:08 ? 00:00:00 [kworker/12:1-events]
还有其他名称的 worker 吗?
默认的叫做 events,但是为什么 share resource 和 large delays 啊 ! 总体来说(外部接口)
- work item 的操作(delay cancel init)
- work queue 的维护(flush create )
- schedule 的操作
内部:
- worker 和 workqeue 之间的 attach detach bind 以及 worker 的各种操作
- attr
接口分析
// 各种work 没有仔细分析了
work_on_cpu_safe
work_on_cpu
queue_rcu_work
work_busy
__init_work
bool queue_work_on(int cpu, struct workqueue_struct *wq, struct work_struct *work);
void drain_workqueue(struct workqueue_struct *wq);
/* obtain a pool matching @attr and create a pwq associating the pool and @wq */
static struct pool_workqueue *alloc_unbound_pwq(struct workqueue_struct *wq, const struct workqueue_attrs *attrs)
struct workqueue_struct *__alloc_workqueue_key(const char *fmt,
unsigned int flags,
int max_active,
struct lock_class_key *key,
const char *lock_name, ...)
// 各种修改属性模型
int apply_workqueue_attrs(struct workqueue_struct *wq,
const struct workqueue_attrs *attrs)
GPL(workqueue_set_max_active);
// 在delay时钟之后将work queue在特定的cpu上
bool queue_delayed_work_on(int cpu, struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay)
bool mod_delayed_work_on(int cpu, struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay)
bool cancel_delayed_work(struct delayed_work *dwork)
delayed_work_timer_fn
cancel_delayed_work
flush_delayed_work
// 取消队列中间的内容
cancel_work_sync
flush_rcu_work
flush_work
// 创建两个自定义的queue的方法
#define create_singlethread_workqueue(name) \
alloc_ordered_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, name)
#define create_workqueue(name) \
alloc_workqueue("%s", __WQ_LEGACY | WQ_MEM_RECLAIM, 1, (name))
flush_workqueue // 各种flush
workqueue_congested
// 两个在头文件中间定义的关键api
schedule_work(struct work_struct *work);
schedule_delayed_work(struct delayed_work *work, unsigned long delay);
用户
有的是自己创建 workqueue 的,比如 virtio blk
static struct virtio_driver virtio_blk = {
.feature_table = features,
.feature_table_size = ARRAY_SIZE(features),
.feature_table_legacy = features_legacy,
.feature_table_size_legacy = ARRAY_SIZE(features_legacy),
.driver.name = KBUILD_MODNAME,
.driver.owner = THIS_MODULE,
.id_table = id_table,
.probe = virtblk_probe,
.remove = virtblk_remove,
.config_changed = virtblk_config_changed,
#ifdef CONFIG_PM_SLEEP
.freeze = virtblk_freeze,
.restore = virtblk_restore,
#endif
};
有的是使用系统的 workqueue:
snd_timer_interrupt => queue_work(system_highpri_wq, &timer->task_work);
INIT_DELAYED_WORK
例如这个,和其他的 workqueue 有什么区别吗? INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
struct delayed_work {
struct work_struct work;
struct timer_list timer;
/* target workqueue and CPU ->timer uses to queue ->work */
struct workqueue_struct *wq;
int cpu;
};
分析下 flush
workqueue_struct::nr_pwqs_to_flush
kvm_tdp_mmu_zap_invalidated_roots+5
kvm_page_track_flush_slot+85
kvm_set_memslot+706
kvm_vm_ioctl+899
__x64_sys_ioctl+148
do_syscall_64+59
entry_SYSCALL_64_after_hwframe+110
/*
* Zap all invalidated roots to ensure all SPTEs are dropped before the "fast
* zap" completes.
*/
void kvm_tdp_mmu_zap_invalidated_roots(struct kvm *kvm)
{
flush_workqueue(kvm->arch.tdp_mmu_zap_wq);
}
- drain_workqueue 和 flush_workqueue 有啥区别?
flush 基本流程:
__flush_workqueue()中等待- wait_for_completion(&this_flusher.done);
- pwq_dec_nr_in_flight() 中如果所有的工作干完了,那么就
- complete(&pwq->wq->first_flusher->done);
color
History: #0
Commit: 73f53c4aa732eced5fcb1844d3d452c30905f20f
Author: Tejun Heo <tj@kernel.org>
Date: Tue 29 Jun 2010 04:07:11 PM CST
workqueue: reimplement workqueue flushing using color coded works
Reimplement workqueue flushing using color coded works. wq has the
current work color which is painted on the works being issued via
cwqs. Flushing a workqueue is achieved by advancing the current work
colors of cwqs and waiting for all the works which have any of the
previous colors to drain.
Currently there are 16 possible colors, one is reserved for no color
and 15 colors are useable allowing 14 concurrent flushes. When color
space gets full, flush attempts are batched up and processed together
when color frees up, so even with many concurrent flushers, the new
implementation won't build up huge queue of flushers which has to be
processed one after another.
Only works which are queued via __queue_work() are colored. Works
which are directly put on queue using insert_work() use NO_COLOR and
don't participate in workqueue flushing. Currently only works used
for work-specific flush fall in this category.
This new implementation leaves only cleanup_workqueue_thread() as the
user of flush_cpu_workqueue(). Just make its users use
flush_workqueue() and kthread_stop() directly and kill
cleanup_workqueue_thread(). As workqueue flushing doesn't use barrier
request anymore, the comment describing the complex synchronization
around it in cleanup_workqueue_thread() is removed together with the
function.
This new implementation is to allow having and sharing multiple
workers per cpu.
Please note that one more bit is reserved for a future work flag by
this patch. This is to avoid shifting bits and updating comments
later.
Signed-off-by: Tejun Heo <tj@kernel.org>
enum {
WORK_STRUCT_PENDING_BIT = 0, /* work item is pending execution */
WORK_STRUCT_INACTIVE_BIT= 1, /* work item is inactive */
WORK_STRUCT_PWQ_BIT = 2, /* data points to pwq */
WORK_STRUCT_LINKED_BIT = 3, /* next work is linked to this one */
WORK_STRUCT_COLOR_SHIFT = 4, /* color for workqueue flushing */
有点难懂,但是其含义估计是:
- 一个 work 存在上述的四种类型,每次 flush work 的时候,先将所有类型的 work item 全部搞完,然后做下一种类型的 work item
核心结构体
pool_workqueue
参考下这个?
https://www.binss.me/blog/analysis-of-linux-workqueue/
了解下 workqueue 的基本使用
一个周期性的函数
自己给自己 delay 就可以了
static void tsc_refine_calibration_work(struct work_struct *work);
static DECLARE_DELAYED_WORK(tsc_irqwork, tsc_refine_calibration_work);
看来 cancel_delayed_work 如果没有正常用的话,很难受
[ 35.439525] systemd-hostnam (793) used greatest stack depth: 11640 bytes left
[ 529.504114] BUG: unable to handle page fault for address: ffffffffc0006048
[ 529.504433] #PF: supervisor write access in kernel mode
[ 529.504626] #PF: error_code(0x0002) - not-present page
[ 529.504819] PGD 3043067 P4D 3043067 PUD 3045067 PMD 10031d067 PTE 0
[ 529.505058] Oops: 0002 [#1] PREEMPT SMP NOPTI
[ 529.505231] CPU: 7 PID: 0 Comm: swapper/7 Tainted: G W O 6.6.0-15029-
gbe3ca57cfb77 #705
[ 529.505564] Hardware name: Martins3 Inc Hacking Alpine, BIOS 12 2022-2-2
[ 529.505807] RIP: 0010:__run_timers+0xd3/0x2d0
[ 529.505974] Code: 74 24 28 89 c1 83 e1 3f 01 d1 89 c9 49 0f b3 09 73 2a 48 8b 5c 24
08 4c 8d 56 08 48 8d 3c cb 48 8b 0f 48 89 0e 48 85 c9 74 04 <48> 89 71 08 48 c7 07 00
00 00 00 41 83 c4 01 4c 89 d6 a8 07 75 0f
[ 529.506648] RSP: 0018:ffffc90000280ec8 EFLAGS: 00010082
[ 529.506841] RAX: 0000000000020007 RBX: ffff888237bdd1f0 RCX: ffffffffc0006040
[ 529.507100] RDX: 0000000000000140 RSI: ffffc90000280ef0 RDI: ffff888237bddc28
[ 529.507361] RBP: dead000000000122 R08: 0000000000000001 R09: ffff888237bdd1a8
[ 529.507620] R10: ffffc90000280ef8 R11: ffff888237bef400 R12: 0000000000000000
[ 529.507879] R13: ffffffff830060c8 R14: 0000000000000001 R15: ffff888237bdd180
[ 529.508140] FS: 0000000000000000(0000) GS:ffff888237bc0000(0000) knlGS:00000000000
00000
[ 529.508436] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 529.508653] CR2: ffffffffc0006048 CR3: 000000010e112000 CR4: 0000000000750ef0
[ 529.508912] PKRU: 55555554
[ 529.509015] Call Trace:
[ 529.509111] <IRQ>
[ 529.509190] ? __die+0x23/0x70
[ 529.509338] ? page_fault_oops+0x181/0x470
[ 529.509496] ? __pfx_cmp_ex_search+0x10/0x10
[ 529.509657] ? exc_page_fault+0xde/0x180
[ 529.509804] ? asm_exc_page_fault+0x26/0x30
[ 529.509961] ? __run_timers+0xd3/0x2d0
[ 529.510102] ? __run_timers+0x5a/0x2d0
[ 529.510245] ? 0xffffffffc000209b
[ 529.510371] run_timer_softirq+0x1d/0x40
[ 529.510517] __do_softirq+0x10b/0x3a7
[ 529.510658] __irq_exit_rcu+0xab/0xd0
[ 529.510798] irq_exit_rcu+0xe/0x20
[ 529.510658] __irq_exit_rcu+0xab/0xd0
[ 529.510798] irq_exit_rcu+0xe/0x20
[ 529.510926] sysvec_apic_timer_interrupt+0x74/0x80
[ 529.511105] </IRQ>
[ 529.511187] <TASK>
[ 529.511270] asm_sysvec_apic_timer_interrupt+0x1a/0x20
[ 529.511460] RIP: 0010:default_idle+0xf/0x20
[ 529.511615] Code: 4c 01 c7 4c 29 c2 e9 72 ff ff ff 90 90 90 90 90 90 90 90 90 90 90
90 90 90 90 90 f3 0f 1e fa eb 07 0f 00 2d 93 62 28 00 fb f4 <fa> c3 cc cc cc cc 66 66
2e 0f 1f 84 00 00 00 00 00 90 90 90 90 90
[ 529.512285] RSP: 0018:ffffc900000e3ee8 EFLAGS: 00000202
[ 529.512478] RAX: 0000000000000007 RBX: 0000000000000007 RCX: 0000000000000001
[ 529.512737] RDX: 4000000000000000 RSI: ffffffff82c51d09 RDI: 00000000000a8be4
[ 529.512997] RBP: ffff888100a5d8c0 R08: 00000000000a8be4 R09: 0000000000000001
[ 529.513258] R10: 0000000000000001 R11: 0000000000000000 R12: 0000000000000000
[ 529.513516] R13: 0000000000000000 R14: ffff888100a5d8c0 R15: 0000000000000000
[ 529.513778] default_idle_call+0x38/0xf0
[ 529.513925] do_idle+0x1f8/0x240
[ 529.514052] cpu_startup_entry+0x2a/0x30
[ 529.514198] start_secondary+0xfc/0x100
[ 529.514345] secondary_startup_64_no_verify+0x178/0x17b
[ 529.514537] </TASK>
[ 529.514621] Modules linked in: [last unloaded: zero_page_ref_fix(O)]
[ 529.514851] CR2: ffffffffc0006048
[ 529.514974] ---[ end trace 0000000000000000 ]---
[ 529.515143] RIP: 0010:__run_timers+0xd3/0x2d0
[ 529.515304] Code: 74 24 28 89 c1 83 e1 3f 01 d1 89 c9 49 0f b3 09 73 2a 48 8b 5c 24
08 4c 8d 56 08 48 8d 3c cb 48 8b 0f 48 89 0e 48 85 c9 74 04 <48> 89 71 08 48 c7 07 00
00 00 00 41 83 c4 01 4c 89 d6 a8 07 75 0f
[ 529.515965] RSP: 0018:ffffc90000280ec8 EFLAGS: 00010082
[ 529.516155] RAX: 0000000000020007 RBX: ffff888237bdd1f0 RCX: ffffffffc0006040
[ 529.516413] RDX: 0000000000000140 RSI: ffffc90000280ef0 RDI: ffff888237bddc28
[ 529.516669] RBP: dead000000000122 R08: 0000000000000001 R09: ffff888237bdd1a8
[ 529.516925] R10: ffffc90000280ef8 R11: ffff888237bef400 R12: 0000000000000000
[ 529.517182] R13: ffffffff830060c8 R14: 0000000000000001 R15: ffff888237bdd180
[ 529.517441] FS: 0000000000000000(0000) GS:ffff888237bc0000(0000) knlGS:00000000000
00000
[ 529.517734] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 529.517945] CR2: ffffffffc0006048 CR3: 000000010e112000 CR4: 0000000000750ef0
[ 529.518206] PKRU: 55555554
[ 529.518309] Kernel panic - not syncing: Fatal exception in interrupt
[ 529.518943] Kernel Offset: disabled
[ 529.519078] ---[ end Kernel panic - not syncing: Fatal exception in interrupt ]---
回答这个问题
https://stackoverflow.com/questions/37216038/whats-the-difference-between-flush-delayed-work-and-cancel-delayed-work-sync
先了解下大致如何使用吧
理解下这几个接口的含义
- cancel_delayed_work : 如果 zero page ref 中,最后直接 cancel ,会出现数据泄漏吗?
- 看来不是, 居然是 flush_delayed_work 会出现问题
- cancel_delayed_work_sync 这个是安全的
- flush_delayed_work : 这个绝对不安全,再仔细看看吧,有点慌张的
为什么 sysfs 中展示的 workqueue 没有 schedule_delayed_work 所挂载的 workqueue
用 gdb 调试了下内核,结果内核卡死了,之前都是 rcu 的警告的
wq_watchdog_timer_fn 中的检测:
Message from syslogd@bogon at Nov 18 19:13:16 ...
kernel:[ 38.547402] BUG: workqueue lockup - pool cpus=4 node=0 flags=0x0 nice=0 stuck for 31s!
Message from syslogd@bogon at Nov 18 19:13:48 ...
kernel:[ 70.834519] BUG: workqueue lockup - pool cpus=5 node=0 flags=0x0 nice=0 stuck for 57s!
sysfs 的支持
/sys/bus/workqueue🔒 🐉
🧀 tree
.
├── devices
│ ├── blkcg_punt_bio -> ../../../devices/virtual/workqueue/blkcg_punt_bio
│ ├── nvme-auth-wq -> ../../../devices/virtual/workqueue/nvme-auth-wq
│ ├── nvme-delete-wq -> ../../../devices/virtual/workqueue/nvme-delete-wq
│ ├── nvme-reset-wq -> ../../../devices/virtual/workqueue/nvme-reset-wq
│ ├── nvme-wq -> ../../../devices/virtual/workqueue/nvme-wq
│ └── writeback -> ../../../devices/virtual/workqueue/writeback
├── drivers
├── drivers_autoprobe
├── drivers_probe
└── uevent
似乎 iouring 专门写了一个更加贴合的 workqueue
找一个具体的例子,驱动在中断启动 workqueue
例如 /sys/devices/virtual/workqueue/nvme-wq/cpumask
- nvme_handle_cqe
- nvme_complete_async_event
- queue_work(nvme_wq, &ctrl->async_event_work);
- nvme_complete_async_event
[ ] unbound 和 bound 的 workqueue 的区别是什么?
- unbound 的 workqueue 也是可以绑定 cpu 的
内部管理的两个 worker 的 flags
enum worker_pool_flags {
/*
* worker_pool flags
*
* A bound pool is either associated or disassociated with its CPU.
* While associated (!DISASSOCIATED), all workers are bound to the
* CPU and none has %WORKER_UNBOUND set and concurrency management
* is in effect.
*
* While DISASSOCIATED, the cpu may be offline and all workers have
* %WORKER_UNBOUND set and concurrency management disabled, and may
* be executing on any CPU. The pool behaves as an unbound one.
*
* Note that DISASSOCIATED should be flipped only while holding
* wq_pool_attach_mutex to avoid changing binding state while
* worker_attach_to_pool() is in progress.
*
* As there can only be one concurrent BH execution context per CPU, a
* BH pool is per-CPU and always DISASSOCIATED.
*/
POOL_BH = 1 << 0, /* is a BH pool */
POOL_MANAGER_ACTIVE = 1 << 1, /* being managed */
POOL_DISASSOCIATED = 1 << 2, /* cpu can't serve workers */
POOL_BH_DRAINING = 1 << 3, /* draining after CPU offline */
};
enum worker_flags {
/* worker flags */
WORKER_DIE = 1 << 1, /* die die die */
WORKER_IDLE = 1 << 2, /* is idle */
WORKER_PREP = 1 << 3, /* preparing to run works */
WORKER_CPU_INTENSIVE = 1 << 6, /* cpu intensive */
WORKER_UNBOUND = 1 << 7, /* worker is unbound */
WORKER_REBOUND = 1 << 8, /* worker was rebound */
WORKER_NOT_RUNNING = WORKER_PREP | WORKER_CPU_INTENSIVE |
WORKER_UNBOUND | WORKER_REBOUND,
};
好好阅读下文档吧
https://docs.kernel.org/core-api/workqueue.html : 连 worker pool 和 workqueue 的关系都没搞清楚
了解下: for_each_bh_worker_pool 和 for_each_cpu_worker_pool
使用 drgn 来分析 workqueue
tools/workqueue/wq_monitor.py
在 fedora 6.7.3 的内核中观测到的
total infl CPUtime CPUitsv CMW/RPR mayday rescued
events 13761 0 0.1 1 47 - -
events_highpri 32 0 0.0 0 0 - -
events_long 4 0 0.0 0 0 - -
events_unbound 33768 0 0.4 - 0 - -
events_freezable 0 0 0.0 0 0 - -
events_power_efficient 4920 0 0.0 0 0 - -
events_freezable_power_ 4 0 0.0 0 0 - -
rcu_gp 621 0 0.0 0 190 0 0
rcu_par_gp 602 0 0.0 0 0 0 0
slub_flushwq 4 0 0.0 0 0 0 0
netns 2 0 0.0 - 0 0 0
mm_percpu_wq 3190 0 0.0 0 0 0 0
cpuset_migrate_mm 0 0 0.0 - 0 - -
inet_frag_wq 6 0 0.0 0 0 0 0
pm 65 0 0.0 0 1 - -
cgroup_destroy 778 0 0.0 0 17 - -
cgroup_pidlist_destroy 0 0 0.0 0 0 - -
writeback 479 0 0.0 - 0 0 0
cgwb_release 17 0 0.0 0 1 - -
cryptd 0 0 0.0 0 0 0 0
kintegrityd 0 0 0.0 0 0 0 0
kblockd 2835 0 0.0 0 0 0 0
blkcg_punt_bio 0 0 0.0 - 0 0 0
kacpid 0 0 0.0 0 0 - -
kacpi_notify 0 0 0.0 0 0 - -
kacpi_hotplug 0 0 0.0 - 0 - -
kec 0 0 0.0 - 0 - -
kec_query 0 0 0.0 0 0 - -
tpm_dev_wq 0 0 0.0 0 0 0 0
ata_sff 0 0 0.0 0 0 0 0
usb_hub_wq 14 0 0.0 0 10 - -
md 0 0 0.0 0 0 0 0
md_misc 0 0 0.0 0 0 - -
md_bitmap 0 0 0.0 - 0 0 0
edac-poller 0 0 0.0 - 0 0 0
rproc_recovery_wq 0 0 0.0 - 0 - -
devfreq_wq 0 0 0.0 - 0 0 0
tc_filter_workqueue 0 0 0.0 - 0 - -
inode_switch_wbs 39 0 0.0 0 0 - -
kthrotld 0 0 0.0 0 0 0 0
acpi_thermal_pm 0 0 0.0 0 0 0 0
scsi_tmf_0 0 0 0.0 - 0 0 0
scsi_tmf_1 0 0 0.0 - 0 0 0
psmouse-smbus 0 0 0.0 0 0 - -
kpsmoused 0 0 0.0 - 0 - -
kdmremove 0 0 0.0 - 0 - -
dm_stripe_wq 0 0 0.0 0 0 - -
dm_bufio_cache 29 0 0.0 0 0 0 0
dm_raid1_wq 0 0 0.0 0 0 - -
sock_diag_events 0 0 0.0 0 0 - -
mld 65 0 0.0 0 0 0 0
ipv6_addrconf 47 0 0.0 0 0 0 0
kstrp 0 0 0.0 - 0 0 0
fscrypt_read_queue 0 0 0.0 - 0 - -
fsverity_read_queue 0 0 0.0 0 0 - -
tr_max_lat_wq 0 0 0.0 - 0 - -
kmpathd 0 0 0.0 0 0 0 0
kmpath_handlerd 0 0 0.0 - 0 0 0
dm_mpath_wq 0 0 0.0 0 0 - -
kaluad 0 0 0.0 0 0 0 0
kmpath_rdacd 0 0 0.0 - 0 0 0
scsi_tmf_2 0 0 0.0 - 0 0 0
virtio-blk 0 0 0.0 0 0 - -
scsi_tmf_3 0 0 0.0 - 0 0 0
nvme-wq 9 0 0.0 - 0 0 0
nvme-reset-wq 0 0 0.0 - 0 0 0
nvme-delete-wq 0 0 0.0 - 0 0 0
nvme-auth-wq 0 0 0.0 - 0 0 0
ttm 0 0 0.0 0 0 0 0
xfsalloc 0 0 0.0 0 0 0 0
xfsdiscard 0 0 0.0 - 0 - -
xfs_mru_cache 0 0 0.0 0 0 0 0
xfs-buf/sda3 3833 0 0.0 0 0 0 0
xfs-conv/sda3 1544 0 0.0 0 1 0 0
xfs-reclaim/sda3 125 0 0.0 0 0 0 0
xfs-blockgc/sda3 5 0 0.0 - 0 0 0
xfs-inodegc/sda3 1894 0 0.1 0 1 0 0
xfs-sync/sda3 29 0 0.0 0 2 - -
xfs-log/sda3 384 0 0.0 0 0 0 0
xfs-cil/sda3 272 0 0.0 - 0 0 0
virtio_vsock 1 0 0.0 0 0 - -
xfs-buf/sda2 29 0 0.0 0 0 0 0
xfs-conv/sda2 0 0 0.0 0 0 0 0
xfs-reclaim/sda2 0 0 0.0 0 0 0 0
xfs-blockgc/sda2 0 0 0.0 - 0 0 0
xfs-inodegc/sda2 0 0 0.0 0 0 0 0
xfs-sync/sda2 29 0 0.0 0 0 - -
xfs-log/sda2 0 0 0.0 0 0 0 0
xfs-cil/sda2 0 0 0.0 - 0 0 0
kvm-irqfd-cleanup 0 0 0.0 0 0 - -
rpciod 0 0 0.0 - 0 0 0
xprtiod 0 0 0.0 - 0 0 0
qrtr_ns_handler 1 0 0.0 - 0 - -
- 应该使用 monitor 来观察自己实现的 workqueue 分析下。
BH workqueue
https://lwn.net/Articles/960041/
What You Always Wanted to Know About Workqueues
https://www.youtube.com/watch?v=zno3WFng61w
内核中的 kworker 分析下
1 I root 8 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/0:0H-events_highpri]
1 I root 23 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/1:0H-events_highpri]
1 I root 28 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/2:0H-events_highpri]
1 I root 33 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/3:0H-events_highpri]
1 I root 38 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/4:0H-events_highpri]
1 I root 43 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/5:0H-events_highpri]
1 I root 48 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/6:0H-events_highpri]
1 I root 53 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/7:0H-events_highpri]
1 I root 58 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/8:0H-events_highpri]
1 I root 63 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/9:0H-events_highpri]
1 I root 68 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/10:0H-events_highpri]
1 I root 73 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/11:0H-events_highpri]
1 I root 78 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/12:0H-events_highpri]
1 I root 83 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/13:0H-events_highpri]
1 I root 88 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/14:0H-events_highpri]
1 I root 93 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/15:0H-events_highpri]
1 I root 98 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/16:0H-events_highpri]
1 I root 103 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/17:0H-events_highpri]
1 I root 108 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/18:0H-events_highpri]
1 I root 113 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/19:0H-events_highpri]
1 I root 118 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/20:0H-events_highpri]
1 I root 123 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/21:0H-events_highpri]
1 I root 128 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/22:0H-events_highpri]
1 I root 133 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/23:0H-events_highpri]
1 I root 138 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/24:0H-events_highpri]
1 I root 143 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/25:0H-events_highpri]
1 I root 148 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/26:0H-events_highpri]
1 I root 153 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/27:0H-events_highpri]
1 I root 158 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/28:0H-events_highpri]
1 I root 163 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/29:0H-events_highpri]
1 I root 168 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/30:0H-events_highpri]
1 I root 173 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/31:0H-events_highpri]
1 I root 196 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/4:1H-events_highpri]
1 I root 287 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/0:1H-events_highpri]
1 I root 289 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/2:1H-events_highpri]
1 I root 292 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/15:1H-events_highpri]
1 I root 294 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/8:1H-kblockd]
1 I root 295 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/10:1H-kblockd]
1 I root 300 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/12:1H-kblockd]
1 I root 363 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/14:1H-kblockd]
1 I root 364 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/16:1H-events_highpri]
1 I root 365 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/28:1H-kblockd]
1 I root 366 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/6:1H-events_highpri]
1 I root 367 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/17:1H-kblockd]
1 I root 368 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/19:1H-kblockd]
1 I root 369 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/18:1H-events_highpri]
1 I root 370 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/20:1H-kblockd]
1 I root 371 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/21:1H-kblockd]
1 I root 372 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/23:1H-events_highpri]
1 I root 373 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/26:1H-kblockd]
1 I root 374 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/24:1H-events_highpri]
1 I root 375 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/25:1H-kblockd]
1 I root 376 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/22:1H-kblockd]
1 I root 377 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/27:1H-kblockd]
1 I root 378 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/29:1H-kblockd]
1 I root 379 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/1:1H-kblockd]
1 I root 380 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/30:1H-events_highpri]
1 I root 382 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/7:1H-events_highpri]
1 I root 383 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/3:1H-events_highpri]
1 I root 384 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/31:1H-kblockd]
1 I root 385 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/9:1H-events_highpri]
1 I root 386 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/5:1H-events_highpri]
1 I root 387 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/11:1H-kblockd]
1 I root 388 2 0 60 -20 - 0 - Jan05 ? 00:00:00 [kworker/13:1H-events_highpri]
1 I root 136334 2 0 80 0 - 0 - Jan05 ? 00:00:00 [kworker/5:1-rcu_par_gp]
1 I root 136625 2 0 80 0 - 0 - Jan05 ? 00:00:00 [kworker/13:0-mm_percpu_wq]
1 I root 136627 2 0 80 0 - 0 - Jan05 ? 00:00:00 [kworker/15:0-rcu_par_gp]
1 I root 136638 2 0 80 0 - 0 - Jan05 ? 00:00:00 [kworker/28:2-rcu_par_gp]
1 I root 136639 2 0 80 0 - 0 - Jan05 ? 00:00:00 [kworker/29:2-rcu_par_gp]
1 I root 343237 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/11:0-rcu_par_gp]
1 I root 421500 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/3:1-rcu_par_gp]
1 I root 490115 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/26:1-rcu_par_gp]
1 I root 511144 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/7:2-rcu_par_gp]
1 I root 527438 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/1:0-mm_percpu_wq]
1 I root 527454 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/9:0-rcu_par_gp]
1 I root 577897 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/3:2-mm_percpu_wq]
1 I root 577898 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/5:0-mm_percpu_wq]
1 I root 577899 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/7:0-mm_percpu_wq]
1 I root 577900 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/9:2-mm_percpu_wq]
1 I root 577901 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/11:2-mm_percpu_wq]
1 I root 577902 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/13:2-rcu_par_gp]
1 I root 577903 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/15:2-mm_percpu_wq]
1 I root 577912 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/26:2-mm_percpu_wq]
1 I root 577913 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/27:0-mm_percpu_wq]
1 I root 577914 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/28:0-mm_percpu_wq]
1 I root 577915 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/29:0-mm_percpu_wq]
1 I root 577916 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/30:0-rcu_gp]
1 I root 577917 2 0 80 0 - 0 - Jan06 ? 00:00:00 [kworker/31:0-rcu_gp]
1 I root 591382 2 0 80 0 - 0 - 13:07 ? 00:00:00 [kworker/25:2-rcu_par_gp]
1 I root 591383 2 0 80 0 - 0 - 13:07 ? 00:00:00 [kworker/24:1-rcu_par_gp]
1 I root 599939 2 0 60 -20 - 0 - 13:43 ? 00:00:02 [kworker/u65:1-rb_allocator]
1 I root 712681 2 0 80 0 - 0 - 14:06 ? 00:00:00 [kworker/22:0-rcu_par_gp]
1 I root 712682 2 0 80 0 - 0 - 14:06 ? 00:00:00 [kworker/21:1-rcu_par_gp]
1 I root 721448 2 0 60 -20 - 0 - 15:02 ? 00:00:01 [kworker/u65:0-rb_allocator]
1 I root 724205 2 0 80 0 - 0 - 15:27 ? 00:00:01 [kworker/u64:5-events_unbound]
1 I root 727332 2 0 80 0 - 0 - 15:38 ? 00:00:00 [kworker/4:1-events]
1 I root 745920 2 0 80 0 - 0 - 15:40 ? 00:00:00 [kworker/19:1-rcu_gp]
1 I root 746034 2 0 80 0 - 0 - 15:40 ? 00:00:00 [kworker/24:2-mm_percpu_wq]
1 I root 746035 2 0 80 0 - 0 - 15:40 ? 00:00:00 [kworker/23:1-events]
1 I root 799037 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/10:1-mm_percpu_wq]
1 I root 799058 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/22:2-mm_percpu_wq]
1 I root 799059 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/10:3-rcu_par_gp]
1 I root 799063 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/6:1-events]
1 I root 801746 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/21:0-mm_percpu_wq]
1 I root 801747 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/20:0-mm_percpu_wq]
1 I root 801749 2 0 80 0 - 0 - 15:47 ? 00:00:00 [kworker/17:0-rcu_gp]
1 I root 838206 2 0 80 0 - 0 - 15:48 ? 00:00:00 [kworker/18:2-rcu_par_gp]
1 I root 838234 2 0 80 0 - 0 - 15:48 ? 00:00:00 [kworker/27:2-rcu_par_gp]
1 I root 856553 2 0 80 0 - 0 - 15:49 ? 00:00:00 [kworker/25:1-mm_percpu_wq]
1 I root 856594 2 0 80 0 - 0 - 15:49 ? 00:00:00 [kworker/2:2-events]
1 I root 856596 2 0 80 0 - 0 - 15:49 ? 00:00:00 [kworker/23:0-rcu_par_gp]
1 I root 856672 2 0 80 0 - 0 - 15:49 ? 00:00:00 [kworker/1:2]
1 I root 893451 2 0 80 0 - 0 - 15:51 ? 00:00:00 [kworker/19:2-mm_percpu_wq]
1 I root 911181 2 0 80 0 - 0 - 15:53 ? 00:00:00 [kworker/8:2-rcu_par_gp]
1 I root 911187 2 0 80 0 - 0 - 15:53 ? 00:00:00 [kworker/12:1-events]
1 I root 911211 2 0 80 0 - 0 - 15:53 ? 00:00:00 [kworker/14:1-rcu_par_gp]
1 I root 942850 2 0 80 0 - 0 - 15:54 ? 00:00:00 [kworker/30:1-mm_percpu_wq]
1 I root 942865 2 0 80 0 - 0 - 15:54 ? 00:00:00 [kworker/31:1-mm_percpu_wq]
1 I root 942946 2 0 80 0 - 0 - 15:54 ? 00:00:00 [kworker/16:1-rcu_gp]
1 I root 967398 2 0 80 0 - 0 - 15:55 ? 00:00:00 [kworker/17:1-mm_percpu_wq]
1 I root 991769 2 0 80 0 - 0 - 15:58 ? 00:00:00 [kworker/u64:6-ext4-rsv-conversion]
1 I root 992255 2 0 80 0 - 0 - 16:00 ? 00:00:00 [kworker/6:0-events]
1 I root 993640 2 0 80 0 - 0 - 16:04 ? 00:00:00 [kworker/14:0-mm_percpu_wq]
1 I root 993641 2 0 80 0 - 0 - 16:04 ? 00:00:00 [kworker/12:2-mm_percpu_wq]
1 I root 993646 2 0 80 0 - 0 - 16:04 ? 00:00:00 [kworker/18:1-mm_percpu_wq]
1 I root 993647 2 0 80 0 - 0 - 16:04 ? 00:00:00 [kworker/16:0-mm_percpu_wq]
1 I root 993666 2 0 80 0 - 0 - 16:04 ? 00:00:00 [kworker/8:0-mm_percpu_wq]
1 I root 1002662 2 0 80 0 - 0 - 16:04 ? 00:00:00 [kworker/2:0-mm_percpu_wq]
1 I root 1002692 2 0 80 0 - 0 - 16:05 ? 00:00:00 [kworker/20:1-rcu_par_gp]
1 I root 1003638 2 0 80 0 - 0 - 16:11 ? 00:00:00 [kworker/0:0-mm_percpu_wq]
1 I root 1003704 2 0 80 0 - 0 - 16:13 ? 00:00:00 [kworker/u64:0-events_unbound]
1 I root 1004272 2 0 80 0 - 0 - 16:16 ? 00:00:00 [kworker/4:2-mm_percpu_wq]
1 D root 1004284 2 0 60 -20 - 0 - 16:16 ? 00:00:00 [kworker/u65:2+i915_flip]
1 I root 1004370 2 0 80 0 - 0 - 16:17 ? 00:00:00 [kworker/0:2-events]
1 I root 1004498 2 0 80 0 - 0 - 16:19 ? 00:00:00 [kworker/u64:1-flush-259:2]
1 I root 1004533 2 0 80 0 - 0 - 16:20 ? 00:00:00 [kworker/u64:2-events_unbound]
1 I root 1005715 2 0 80 0 - 0 - 16:22 ? 00:00:00 [kworker/4:0-events]
1 I root 1005724 2 0 80 0 - 0 - 16:22 ? 00:00:00 [kworker/0:1-events]
0 S martins3 1007175 1006549 0 80 0 - 55616 pipe_r 16:25 pts/13 00:00:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn --exclude-dir=.idea --exclude-dir=.tox kworker
workqueue 的这些错误都意味着什么?
内核版本为 : 6.8.0-52-generic
[79649.110683] workqueue: psi_avgs_work hogged CPU for >13333us 8 times, consider switching to WQ_UNBOUND
[86239.960144] workqueue: fqdir_free_fn hogged CPU for >13333us 8 times, consider switching to WQ_UNBOUND
[92013.599816] workqueue: sync_rcu_exp_select_node_cpus hogged CPU for >13333us 32 times, consider switching to WQ_UNBOUND
[103166.244410] workqueue: drain_vmap_area_work hogged CPU for >13333us 8 times, consider switching to WQ_UNBOUND
[109066.402519] workqueue: psi_avgs_work hogged CPU for >13333us 16 times, consider switching to WQ_UNBOUND
[133255.907087] workqueue: fqdir_free_fn hogged CPU for >13333us 16 times, consider switching to WQ_UNBOUND
[143244.819165] workqueue: sync_rcu_exp_select_node_cpus hogged CPU for >13333us 64 times, consider switching to WQ_UNBOUND
[175896.755772] workqueue: drain_vmap_area_work hogged CPU for >13333us 16 times, consider switching to WQ_UNBOUND
[178861.615113] workqueue: free_ipc hogged CPU for >13333us 4 times, consider switching to WQ_UNBOUND
[179168.757410] workqueue: psi_avgs_work hogged CPU for >13333us 32 times, consider switching to WQ_UNBOUND
[220928.508720] workqueue: fqdir_free_fn hogged CPU for >13333us 32 times, consider switching to WQ_UNBOUND
plka 说的记录 : 4 Work Queue
Work queues are a different form of deferring work from what we have looked at so far. Work queues defer work into a kernel thread—this bottom half always runs in process context. Thus, code deferred to a work queue has all the usual benefits of process context. Most important, work queues are schedulable and can therefore sleep.
If you need a schedulable entity to perform your bottom-half processing, you need work queues.They are the only bottom-half mechanisms that run in process context, and thus, the only ones that can sleep.
These kernel threads are called worker threads. Work queues let your driver create a special worker thread to handle deferred work.
The default worker threads are called events/n where n is the processor number; there is one per processor.
The default worker thread handles deferred work from multiple locations. Many drivers in the kernel defer their bottom-half work to the default thread. Unless a driver or subsystem has a strong requirement for creating its own thread, the default thread is preferred.
Nothing stops code from creating its own worker thread, however.This might be advantageous if you perform large amounts of processing in the worker thread. Processorintense and performance-critical work might benefit from its own thread.This also lightens the load on the default threads, which prevents starving the rest of the queued work.
4.1 Implementing Work Queues
/*
* The externally visible workqueue. It relays the issued work items to
* the appropriate worker_pool through its pool_workqueues.
*/
struct workqueue_struct {
struct list_head pwqs; /* WR: all pwqs of this wq */
struct list_head list; /* PR: list of all workqueues */
struct mutex mutex; /* protects this wq */
int work_color; /* WQ: current work color */
int flush_color; /* WQ: current flush color */
atomic_t nr_pwqs_to_flush; /* flush in progress */
struct wq_flusher *first_flusher; /* WQ: first flusher */
struct list_head flusher_queue; /* WQ: flush waiters */
struct list_head flusher_overflow; /* WQ: flush overflow list */
struct list_head maydays; /* MD: pwqs requesting rescue */
struct worker *rescuer; /* I: rescue worker */
int nr_drainers; /* WQ: drain in progress */
int saved_max_active; /* WQ: saved pwq max_active */
struct workqueue_attrs *unbound_attrs; /* PW: only for unbound wqs */
struct pool_workqueue *dfl_pwq; /* PW: only for unbound wqs */
#ifdef CONFIG_SYSFS
struct wq_device *wq_dev; /* I: for sysfs interface */
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
char name[WQ_NAME_LEN]; /* I: workqueue name */
/*
* Destruction of workqueue_struct is sched-RCU protected to allow
* walking the workqueues list without grabbing wq_pool_mutex.
* This is used to dump all workqueues from sysrq.
*/
struct rcu_head rcu;
/* hot fields used during command issue, aligned to cacheline */
unsigned int flags ____cacheline_aligned; /* WQ: WQ_* flags */
struct pool_workqueue __percpu *cpu_pwqs; /* I: per-cpu pwqs */
struct pool_workqueue __rcu *numa_pwq_tbl[]; /* PWR: unbound pwqs indexed by node */
};
struct work_struct {
atomic_long_t data;
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
These structures are strung into a linked list, one for each type of queue on each
processor. For example, there is one list of deferred work for the generic thread, per
processor. When a worker thread wakes up, it runs any work in its list. As it completes
work, it removes the corresponding work_struct entries from the linked list.When the
list is empty, it goes back to sleep.
struct work_struct 是 worker 的代表
/**
* worker_thread - the worker thread function
* @__worker: self
*
* The worker thread function. All workers belong to a worker_pool -
* either a per-cpu one or dynamic unbound one. These workers process all
* work items regardless of their specific target workqueue. The only
* exception is work items which belong to workqueues with a rescuer which
* will be explained in rescuer_thread().
*
* Return: 0
*/
static int worker_thread(void *__worker)
{
struct worker *worker = __worker;
struct worker_pool *pool = worker->pool;
/* tell the scheduler that this is a workqueue worker */
set_pf_worker(true);
woke_up:
spin_lock_irq(&pool->lock);
/* am I supposed to die? */
if (unlikely(worker->flags & WORKER_DIE)) {
spin_unlock_irq(&pool->lock);
WARN_ON_ONCE(!list_empty(&worker->entry));
set_pf_worker(false);
set_task_comm(worker->task, "kworker/dying");
ida_simple_remove(&pool->worker_ida, worker->id);
worker_detach_from_pool(worker);
kfree(worker);
return 0;
}
worker_leave_idle(worker);
recheck:
/* no more worker necessary? */
if (!need_more_worker(pool))
goto sleep;
/* do we need to manage? */
if (unlikely(!may_start_working(pool)) && manage_workers(worker))
goto recheck;
/*
* ->scheduled list can only be filled while a worker is
* preparing to process a work or actually processing it.
* Make sure nobody diddled with it while I was sleeping.
*/
WARN_ON_ONCE(!list_empty(&worker->scheduled));
/*
* Finish PREP stage. We're guaranteed to have at least one idle
* worker or that someone else has already assumed the manager
* role. This is where @worker starts participating in concurrency
* management if applicable and concurrency management is restored
* after being rebound. See rebind_workers() for details.
*/
worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND);
do {
struct work_struct *work =
list_first_entry(&pool->worklist,
struct work_struct, entry);
pool->watchdog_ts = jiffies;
if (likely(!(*work_data_bits(work) & WORK_STRUCT_LINKED))) {
/* optimization path, not strictly necessary */
process_one_work(worker, work);
if (unlikely(!list_empty(&worker->scheduled)))
process_scheduled_works(worker);
} else {
move_linked_works(work, &worker->scheduled, NULL);
process_scheduled_works(worker);
}
} while (keep_working(pool));
worker_set_flags(worker, WORKER_PREP);
sleep:
/*
* pool->lock is held and there's no work to process and no need to
* manage, sleep. Workers are woken up only while holding
* pool->lock or from local cpu, so setting the current state
* before releasing pool->lock is enough to prevent losing any
* event.
*/
worker_enter_idle(worker);
__set_current_state(TASK_IDLE);
spin_unlock_irq(&pool->lock);
schedule();
goto woke_up;
}
面目全非了,skip the whole workqueue
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。