Buddy System
从这个角度介绍是很好的: https://richardweiyang-2.gitbook.io/kernel-exploring/00-memory_a_bottom_up_view/13-physical-layer-partition
-
整理这个: https://richardweiyang-2.gitbook.io/kernel-exploring/00-memory_a_bottom_up_view/13-physical-layer-partition
-
同时整理 compound page, folio, hugetlb 之类的东西
get_page_from_freelist 就是 buddy systemd 的
核心实现,后面之所以有那么多的内容,只是由于内存不足,然后fallback处理之类的啊
问题
/**
* __free_pages - Free pages allocated with alloc_pages().
* @page: The page pointer returned from alloc_pages().
* @order: The order of the allocation.
*
* This function can free multi-page allocations that are not compound
* pages. It does not check that the @order passed in matches that of
* the allocation, so it is easy to leak memory. Freeing more memory
* than was allocated will probably emit a warning.
*
* If the last reference to this page is speculative, it will be released
* by put_page() which only frees the first page of a non-compound
* allocation. To prevent the remaining pages from being leaked, we free
* the subsequent pages here. If you want to use the page's reference
* count to decide when to free the allocation, you should allocate a
* compound page, and use put_page() instead of __free_pages().
*
* Context: May be called in interrupt context or while holding a normal
* spinlock, but not in NMI context or while holding a raw spinlock.
*/
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
else if (!PageHead(page))
while (order-- > 0)
free_the_page(page + (1 << order), order);
}
这个 free 真的让人疑惑:
- free 不应该就是释放 page 吗?
-
为什么不是 PageHead 就可以释放?
- 是不是 Movable 的有 zone 和 page 吧
Node 0, zone Movable pages free 0 boost 0 min 0 low 0 high 0 spanned 0 present 0 managed 0 cma 0 protection: (0, 0, 0, 0, 0) - 跟踪一下 migrate_pages 这个系统调用
问题
- per_cpu_pageset 到底是用于管理缓存的还是管理 migration 的?
- 为什么定义如此之多的 gfp_t 类型,都是用来做什么的 ? 都是如何被一一化解的 ?
- imgration 的内容似乎就是简单的通过创建多个 list 解决的
- buddy system 如何确定那些 page 的 imagration 的类型 ?
- watermark 不同数值会导致分配的策略变化是什么 ?
-
找到 cache hot-cold page 的内容位置 ?
- alloc_pages 调用链条是什么?
- fallback list ?
- pageset watermark 如何融合的 ?
- 如何通过 zone movable 机制实现 anti-fragmentation
对于每一个 node 的初始化,同时会初始化 page 的 flags 相关的内容 ```c /*
- Allocate the accumulated non-linear sections, allocate a mem_map
- for each and record the physical to section mapping. */ void __init sparse_init(void)
// 很好,又回来了 void __init paging_init(void)
> 似乎就是简单的分析gfp_t来分析migration,因为gfp其实在 alloc_pages 参数加以指定。
```c
static inline int gfpflags_to_migratetype(const gfp_t gfp_flags)
{
VM_WARN_ON((gfp_flags & GFP_MOVABLE_MASK) == GFP_MOVABLE_MASK);
BUILD_BUG_ON((1UL << GFP_MOVABLE_SHIFT) != ___GFP_MOVABLE);
BUILD_BUG_ON((___GFP_MOVABLE >> GFP_MOVABLE_SHIFT) != MIGRATE_MOVABLE);
if (unlikely(page_group_by_mobility_disabled))
return MIGRATE_UNMOVABLE;
/* Group based on mobility */
return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
}
// 当前环境信息以及gfp_t的信息在此处完成
static inline bool prepare_alloc_pages(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask,
struct alloc_context *ac, gfp_t *alloc_mask,
unsigned int *alloc_flags)
{
基本流程
__alloc_pages+1
folio_alloc+23
__filemap_get_folio+441
pagecache_get_page+21
ext4_da_write_begin+238
generic_perform_write+193
ext4_buffered_write_iter+123
io_write+280
io_issue_sqe+1182
io_wq_submit_work+129
io_worker_handle_work+615
io_wqe_worker+766
ret_from_fork+34
__alloc_pages+1
alloc_pages_vma+143
__handle_mm_fault+2562
handle_mm_fault+178
do_user_addr_fault+460
exc_page_fault+103
asm_exc_page_fault+30
__alloc_pages+1
__get_free_pages+13
__pollwait+137
n_tty_poll+105
tty_poll+102
do_sys_poll+652
__x64_sys_poll+162
do_syscall_64+59
entry_SYSCALL_64_after_hwframe+68
TODO
- 构建一个 memory 启动的基本流程:
#0 sparse_init_one_section (flags=8, usage=0xffff88813fffab00, mem_map=0xffffea0000000000, pnum=0, ms=0xffff88813fffb000) at mm/sparse.c:306 #1 sparse_init_nid (nid=nid@entry=0, pnum_begin=pnum_begin@entry=0, pnum_end=pnum_end@entry=40, map_count=<optimized out>) at mm/sparse.c:537 #2 0xffffffff8330ae45 in sparse_init () at mm/sparse.c:580 #3 0xffffffff832f7eba in paging_init () at arch/x86/mm/init_64.c:815 #4 0xffffffff832e78e3 in setup_arch (cmdline_p=cmdline_p@entry=0xffffffff82a03f10) at arch/x86/kernel/setup.c:1253 #5 0xffffffff832ddc56 in start_kernel () at init/main.c:952 #6 0xffffffff81000145 in secondary_startup_64 () at arch/x86/kernel/head_64.S:358
基本流程
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *__alloc_pages(gfp_t gfp, unsigned int order, int preferred_nid,
nodemask_t *nodemask)
__alloc_pages: 分配struct alloc_context- prepare_alloc_pages : 组装出来
alloc_context- gfp_migratetype : 将 gfp_t 中的两个 bit 提取出来
- get_page_from_freelist : 选择 zone 和 migrate type
- rmqueue
- rmqueue_pcplist : size=1 有特殊通道
__rmqueue_pcplistrmqueue_bulk:一次多取出几个放到
- rmqueue_buddy
__rmqueue_smallest__rmqueue__rmqueue_smallest:常规的伙伴系统__rmqueue_cma_fallback__rmqueue_fallback
- rmqueue_pcplist : size=1 有特殊通道
- rmqueue
- prepare_alloc_pages : 组装出来
- free_pages
__free_pages- free_the_page
- free_unref_page :释放为 pcp pages
__free_pages_ok:释放普通的__free_one_page:常规的伙伴系统
page allocator
为什么 page allocator 如此复杂 ?
- 当内存不够的时候,使用 compaction 和 page reclaim 压榨一些内存出来
- 为了性能 : percpu
__alloc_pages_nodemask 是整个 buddy allocator 的核心,各种调用的函数都是辅助,其 alloc_context 之后,然后调用两个关键
- get_page_from_freelist : 从 freelist 直接中间获取
__alloc_pages_slowpath: 无法从 freelist 中间获取,那么调整 alloc_flags,重新使用 get_page_from_freelist 进行尝试,如果还是失败,使用__alloc_pages_direct_reclaim=>__perform_reclaim=> try_to_free_pages : 通过 reclaim page 进行分配__alloc_pages_direct_compact=> try_to_compact_pages : 通过 compaction 维持生活似乎整个调用路径非常清晰,但是 hugepage 和 mempolicy 的效果体现在哪里的细节还是需要深究一下。
解除疑惑 : 为什么 alloc_pages 没有 mempolicy 的参数 ?
static inline struct page * alloc_pages(gfp_t gfp_mask, unsigned int order) { return alloc_pages_current(gfp_mask, order); }
/**
* alloc_pages_current - Allocate pages.
*
* @gfp:
* %GFP_USER user allocation,
* %GFP_KERNEL kernel allocation,
* %GFP_HIGHMEM highmem allocation,
* %GFP_FS don't call back into a file system.
* %GFP_ATOMIC don't sleep.
* @order: Power of two of allocation size in pages. 0 is a single page.
*
* Allocate a page from the kernel page pool. When not in
* interrupt context and apply the current process NUMA policy.
* Returns NULL when no page can be allocated.
*/
struct page *alloc_pages_current(gfp_t gfp, unsigned order)
{
struct mempolicy *pol = &default_policy;
struct page *page;
if (!in_interrupt() && !(gfp & __GFP_THISNODE))
pol = get_task_policy(current);
/*
* No reference counting needed for current->mempolicy
* nor system default_policy
*/
if (pol->mode == MPOL_INTERLEAVE)
page = alloc_page_interleave(gfp, order, interleave_nodes(pol));
else
page = __alloc_pages_nodemask(gfp, order,
policy_node(gfp, pol, numa_node_id()),
policy_nodemask(gfp, pol));
return page;
}
EXPORT_SYMBOL(alloc_pages_current);
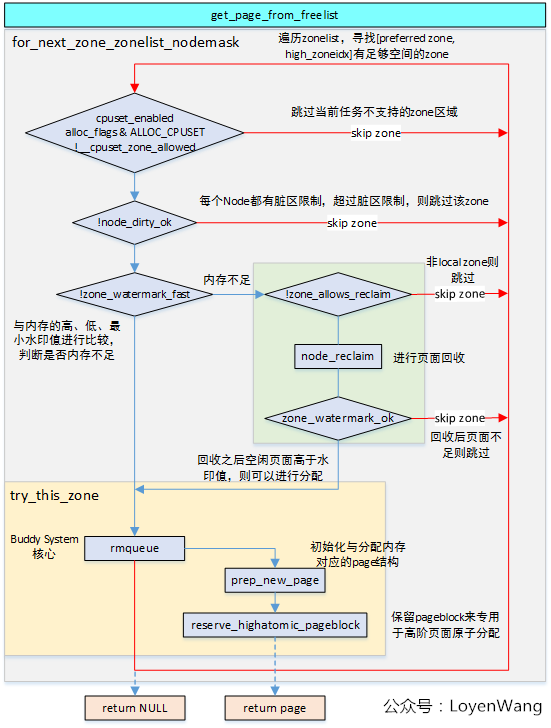
happy path : get_page_from_freelist
- 检查一下 dirty 数量是否超标: node_dirty_ok
- 检查内存剩余数量 : zone_watermark_fast,如果超标,使用 node_reclaim 回收.
- 从合乎要求的 zone 里面获取页面 : rmqueue
happy path : requeue
- 如果大小为 order 为 1,从 percpu cache 中间获取: rmqueue_pcplist
- 否则调用
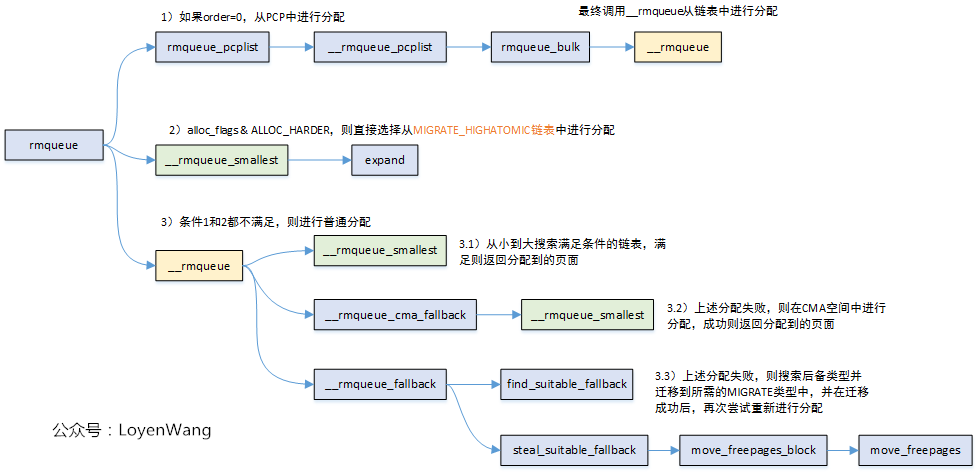
__rmqueue,__rmqueue首先进行使用__rmqueue_smallest进行尝试,如果不行,调用__rmqueue_fallback在 fallback list 中间查找。 __rmqueue_smallest就是介绍 buddy allocator 的理论实现的部分了
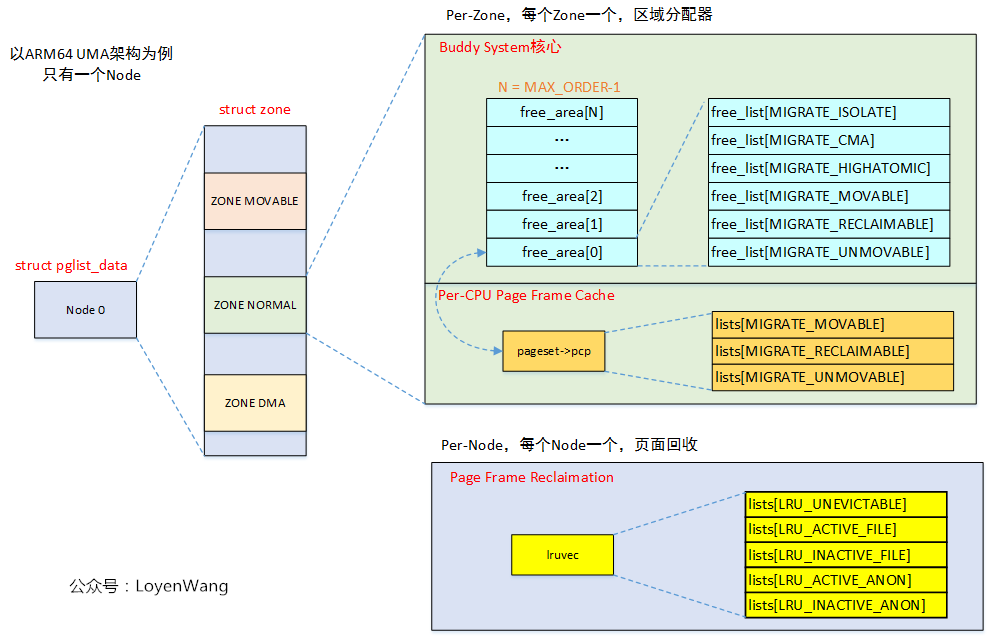
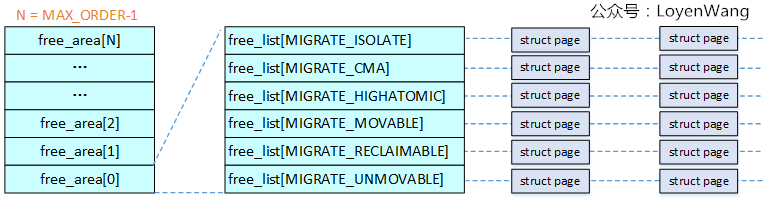
-
why allocate pages per zone, but reclaim pages per node ?
-
cat /proc/pagetypeinfo && cat /proc/pagetypeinfo , check it in spare time
-
gfp_mask and alloc_flags
- gfp_to_alloc_flags
- include/linux/gfp.h contains clear comments for gfp_mask
quick and slow path of allocation:
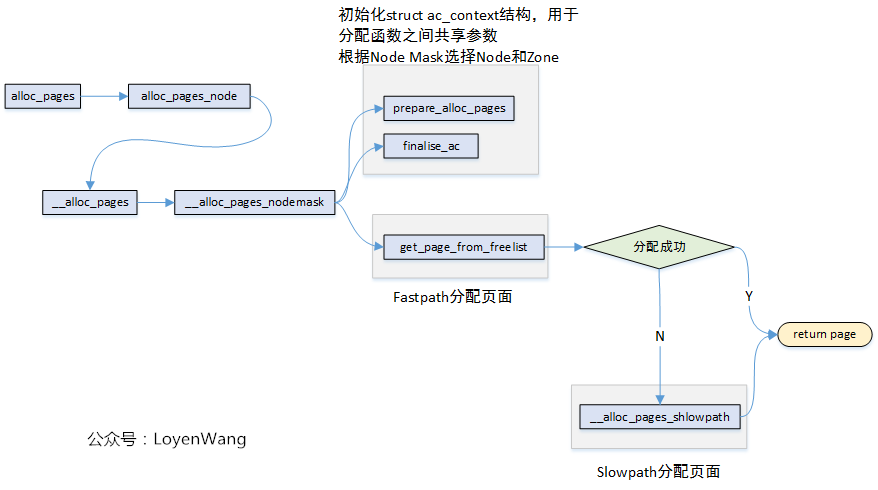

- So what’s ALLOC_HARDER
- gfp_to_alloc_flags() :
- rmqueue() : will try
MIGRATE_HIGHATOMICtype memory immediately with ALLOC_HARDER
page free
当 order = 0 时,会使用 Per-CPU Page Frame 来释放,其中:
- MIGRATE_UNMOVABLE, MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE 三个按原来的类型释放;
- MIGRATE_CMA, MIGRATE_HIGHATOMIC 类型释放到 MIGRATE_UNMOVABLE 类型中;
- MIGRATE_ISOLATE 类型释放到 Buddy 系统中;
-
此外,在 PCP 释放的过程中,发生溢出时,会调用 free_pcppages_bulk()来返回给 Buddy 系统。来一张图就清晰了:
- what if order != 0 ?

page_alloc
TODO
- 浏览文件,确定其中主要干的事情是什么
static __always_inline bool free_pages_prepare(struct page *page,
unsigned int order, bool check_free) // 似乎用于debug 其中包含各种辅助函数
- CONFIG_CMA 和 CONFIG_DEFERRED_STRUCT_PAGE_INIT
- expand()
-
split_page
- alloc_contig_range 和 isolation 的关系
- CONFIG_SPARSEMEM 的效果是什么 ?
- sysctl 的配置内容是什么 ?
-
alloc_page 设计到各种机制是什么 ?
- fallback 是不是指 : 首先从 ZONE_NORMAL 中间查询,没有就切换到 ZONE_DMA32 中间,在 zone 中间按照移动性质进行 fallback ?
zone->watermark_boost的作用是什么 ?
layout
| desc | line |
|---|---|
| free_one_page | 1000 |
| CONFIG_CMA CONFIG_DEFERRED_STRUCT_PAGE_INIT 都没有配置,各种 check | 2000 |
| dequeue 以及 fallback 并且为 vmscan 提供 free_unref_page_list | 2800 |
| watermark 以及 get_page_from_freelist 及其各种封装函数 | 3753 |
__alloc_pages_ |
4400 |
| page_frag(不用关注的东西,skbuff.c) alloc_pages_exact meminfo 相关的消息 | 5000 |
| build_all_zonelists 以及其各种辅助函数,但是其具体 zone 的 fallback 机制的使用并不清楚 | 5545 |
| free_area_init_core 其中持有大量关于 pcp 的相关的初始化 | 7000 |
sysctl 配置函数 和 *_contig_range |
8000 |
reserve
- 但是 reserve 的作用是什么 ?
struct zone::lowmem_reserve
calculate_totalreserve_pages
calculate_totalreserve_pages
reclaim
/* Perform direct synchronous page reclaim */
static int
__perform_reclaim(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac)
// 其实还是 reclaim 中间的一部分
__alloc_pages_* 系列
简单的递进关系:
__alloc_pages_nodemask : 核心
__alloc_pages_slowpath : // TODO 对应的fastpath 是什么,为什么被划分为两者
__alloc_pages_may_oom
__alloc_pages_direct_compact
备忘
确信
- CONFIG_SPARSEMEM : mem_section
- compound page: 550
- PageBuddy() indicates that the page is free and in the buddy system
几乎确定
- migratetype 的种类 : isolated pageblock, normal pageblock
- migratetype 和 pageblock 关联的 : get_pfnblock_migratetype
- migrate 存在 fallback,而且连 zone 也是存在 fallback 的
isolate
int __isolate_free_page(struct page *page, unsigned int order)
// isolate 其中的
free 机制
/* At each level, we keep a list of pages, which are heads of continuous */
/* free pages of length of (1 << order) and marked with PageBuddy. */
/* Page's order is recorded in page_private(page) field. */
// 1. set_page_order
// 2. page_is_buddy
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype)
// todo page 和 pfn 不是一一对应的吗 ?
if (likely(!is_migrate_isolate(migratetype)))
__mod_zone_freepage_state(zone, 1 << order, migratetype); // mod 是什么意思是,这个甘薯干啥的?
// todo done_merging 的处理 pageblock_order 的没有看懂
// isolate 和 normal 的区别是什么 ?
// 似乎只能在一个 pageblock 中间合并
free_unref_page_prepare
free_unref_page_commit
free_unref_page
free_unref_page_list
此处的 unref 的含义是 : shrink_active_list
alloc 机制
__rmqueue_smallest : 都容易理解,除了调用的 expand()
__rmqueue :
__rmqueue_fallback :
move_freepages : 切换 pages 中间 migratetype
move_freepages_block :
steal_suitable_fallback :
/*
* Reserve a pageblock for exclusive use of high-order atomic allocations if
* there are no empty page blocks that contain a page with a suitable order
*/
static void reserve_highatomic_pageblock(struct page *page, struct zone *zone,
unsigned int alloc_order)
/*
* Used when an allocation is about to fail under memory pressure. This
* potentially hurts the reliability of high-order allocations when under
* intense memory pressure but failed atomic allocations should be easier
* to recover from than an OOM.
*
* If @force is true, try to unreserve a pageblock even though highatomic
* pageblock is exhausted.
*/
static bool unreserve_highatomic_pageblock(const struct alloc_context *ac,
bool force)
// 将 reserved 的释放一下
@todo 请问,什么叫做 high order atomic allocation
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
// 首先扫描出来一个 zone 然后对于该 zone rmqueue,从这一个函数引入了 alloc_context。
/*
* Structure for holding the mostly immutable allocation parameters passed
* between functions involved in allocations, including the alloc_pages*
* family of functions.
*
* nodemask, migratetype and high_zoneidx are initialized only once in
* __alloc_pages_nodemask() and then never change.
*
* zonelist, preferred_zone and classzone_idx are set first in
* __alloc_pages_nodemask() for the fast path, and might be later changed
* in __alloc_pages_slowpath(). All other functions pass the whole strucure
* by a const pointer.
*/
struct alloc_context {
struct zonelist *zonelist;
nodemask_t *nodemask;
struct zoneref *preferred_zoneref;
int migratetype;
enum zone_type high_zoneidx;
bool spread_dirty_pages;
};
// 几乎 immutable
// 接下来,各种对于 get_page_from_freelist 的封装函数
static inline struct page *
__alloc_pages_cpuset_fallback(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags,
const struct alloc_context *ac)
static inline struct page *
__alloc_pages_may_oom(gfp_t gfp_mask, unsigned int order,
const struct alloc_context *ac, unsigned long *did_some_progress)
/* Try memory compaction for high-order allocations before reclaim */
static struct page *
__alloc_pages_direct_compact(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio, enum compact_result *compact_result)
compact
static inline bool
should_compact_retry(struct alloc_context *ac, int order, int alloc_flags,
enum compact_result compact_result,
enum compact_priority *compact_priority,
int *compaction_retries)
@todo 附近的好几个函数并没有分析
pcpset
per_cpu_pages 又叫做 pageset 是吗 ? 此时的 cache 表示什么 pcp 如何确定 cpu 中间的私有的 cache 的数量,如果 cpu 没有 private cache 的内容,那么这个东西是不是自动被 disable 掉啊 !
pageset is an array that holds as many entries as the maximum possible number of CPUs that the system
can accommodate.
static void free_pcppages_bulk(struct zone *zone, int count,
struct per_cpu_pages *pcp)
// 将 pcp 中间的各种 list 的page全部取出来,然后一一 __free_one_page
drain_pages_zone
drain_zone_pages
drain_pages
drain_local_pages
drain_all_pages
@todo 认为 pcp 是和 numa 相关的 @todo please source trail it !
rmqueue
rmqueue_pcplist
__rmqueue_pcplist
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
很有意思的机制,所以为什么 order-0 allocation 被放入到其中的 ?
- 所以 pcp 什么时候需要补充货源呢 ?
init
free_unref_page_list
- shrink_page_list 将会对于此位置进行调用,在调用此之前,dirty,unmap,以及 radix_tree remove 工作已经完成
/*
* Free a 0-order page
*/
void free_unref_page(struct page *page)
{
unsigned long flags;
unsigned long pfn = page_to_pfn(page);
if (!free_unref_page_prepare(page, pfn))
return;
local_irq_save(flags);
free_unref_page_commit(page, pfn);
local_irq_restore(flags);
}
// 似乎 free_unref_page_list 和 free_unref_page 的升级版本
/*
* Free a list of 0-order pages
*/
void free_unref_page_list(struct list_head *list)
{
struct page *page, *next;
unsigned long flags, pfn;
int batch_count = 0;
/* Prepare pages for freeing */
list_for_each_entry_safe(page, next, list, lru) {
pfn = page_to_pfn(page);
if (!free_unref_page_prepare(page, pfn))
list_del(&page->lru);
set_page_private(page, pfn);
}
local_irq_save(flags);
list_for_each_entry_safe(page, next, list, lru) {
unsigned long pfn = page_private(page);
set_page_private(page, 0);
trace_mm_page_free_batched(page);
free_unref_page_commit(page, pfn);
/*
* Guard against excessive IRQ disabled times when we get
* a large list of pages to free.
*/
if (++batch_count == SWAP_CLUSTER_MAX) {
local_irq_restore(flags);
batch_count = 0;
local_irq_save(flags);
}
}
local_irq_restore(flags);
}
initialization of zone
- 到底如何初始化 ? zone 中间的每一个内容,如何初始化每一个 zone ?
initialization of zone : Range
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*/
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
-
这 NM 注释有毒啊 !
managed_pages = present_pages - reserved_pages; reserved_pages = present_pages - managed_pages
zone_start_pfn :
max_low_pfn 全局变量
- 所以,你知道什么叫做 low memory 吗 ?
-
都是在 setup_arch 中间初始化的吧 !
- 在 64bit 的空间中间 :max_low_pfn 和 max_fpn 相等的
- 当在 32bit 的时候,max_low_pfn 被限制在 4G 的空间之内
/* /home/shen/Core/linux/mm/memblock.c */
unsigned long max_low_pfn; // Page frame number of the last page frame directly mapped by the kernel (low memory) // todo 可以分析一下 low memory 的初始化的过程 !
unsigned long min_low_pfn;
unsigned long max_pfn; // Page frame number of the last usable page frame
unsigned long long max_possible_pfn;
free_area_init_nodes
- 我们的好朋友 : 当 sparse 完成内存的基本管理(pfn 和 struct page 互相映射)之后,然后就可以开始了
-
这应该是初始化工作的万恶之源吧 ! @todo 等待验证
- 对于我的电脑,x86 并且 内存大于 4G,所以 max_low_pfn 就是最大可用
- movable 的类型没有初始化 !
void __init zone_sizes_init(void)
{
unsigned long max_zone_pfns[MAX_NR_ZONES];
memset(max_zone_pfns, 0, sizeof(max_zone_pfns));
max_zone_pfns[ZONE_DMA] = min(MAX_DMA_PFN, max_low_pfn);
max_zone_pfns[ZONE_DMA32] = min(MAX_DMA32_PFN, max_low_pfn);
max_zone_pfns[ZONE_NORMAL] = max_low_pfn;
free_area_init_nodes(max_zone_pfns);
}
/**
* free_area_init_nodes - Initialise all pg_data_t and zone data
* @max_zone_pfn: an array of max PFNs for each zone
*
* This will call free_area_init_node() for each active node in the system.
* Using the page ranges provided by memblock_set_node(), the size of each
* zone in each node and their holes is calculated. If the maximum PFN
* between two adjacent zones match, it is assumed that the zone is empty.
* For example, if arch_max_dma_pfn == arch_max_dma32_pfn, it is assumed
* that arch_max_dma32_pfn has no pages. It is also assumed that a zone
* starts where the previous one ended. For example, ZONE_DMA32 starts
* at arch_max_dma_pfn.
*/
void __init free_area_init_nodes(unsigned long *max_zone_pfn)
{
unsigned long start_pfn, end_pfn;
int i, nid;
/* Record where the zone boundaries are */
memset(arch_zone_lowest_possible_pfn, 0,
sizeof(arch_zone_lowest_possible_pfn));
memset(arch_zone_highest_possible_pfn, 0,
sizeof(arch_zone_highest_possible_pfn));
start_pfn = find_min_pfn_with_active_regions();
// 找到整个node 第一个可用的 pfn,这不是物理内存,而是在 memblock 的 memblock.memory
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE) // ZONE_MOVABLE 主要用于处理 memory hotplug 的内容,不用在乎 !
continue;
end_pfn = max(max_zone_pfn[i], start_pfn);
arch_zone_lowest_possible_pfn[i] = start_pfn; // 第一个开始是来自于 memblock, 之后保证都是链接在一起的
arch_zone_highest_possible_pfn[i] = end_pfn;
start_pfn = end_pfn; // 区间就是通过实现配置的
}
/* Find the PFNs that ZONE_MOVABLE begins at in each node */
memset(zone_movable_pfn, 0, sizeof(zone_movable_pfn));
find_zone_movable_pfns_for_nodes(); // 不用处理,所以,由于DMA 映射区间有限,所以不同的区间的使用方法不同
/* Print out the zone ranges */
pr_info("Zone ranges:\n");
for (i = 0; i < MAX_NR_ZONES; i++) {
if (i == ZONE_MOVABLE)
continue;
pr_info(" %-8s ", zone_names[i]);
if (arch_zone_lowest_possible_pfn[i] ==
arch_zone_highest_possible_pfn[i])
pr_cont("empty\n");
else
pr_cont("[mem %#018Lx-%#018Lx]\n",
(u64)arch_zone_lowest_possible_pfn[i]
<< PAGE_SHIFT,
((u64)arch_zone_highest_possible_pfn[i]
<< PAGE_SHIFT) - 1);
}
/* Print out the PFNs ZONE_MOVABLE begins at in each node */
pr_info("Movable zone start for each node\n");
for (i = 0; i < MAX_NUMNODES; i++) {
if (zone_movable_pfn[i])
pr_info(" Node %d: %#018Lx\n", i,
(u64)zone_movable_pfn[i] << PAGE_SHIFT);
}
/*
* Print out the early node map, and initialize the
* subsection-map relative to active online memory ranges to
* enable future "sub-section" extensions of the memory map.
*/
pr_info("Early memory node ranges\n");
for_each_mem_pfn_range(i, MAX_NUMNODES, &start_pfn, &end_pfn, &nid) { // 对于所有 node 找到 memory 的 start_fpn end_fpn 以及对应的 nid
pr_info(" node %3d: [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
((u64)end_pfn << PAGE_SHIFT) - 1);
subsection_map_init(start_pfn, end_pfn - start_pfn);
}
/* Initialise every node */
mminit_verify_pageflags_layout();
setup_nr_node_ids(); // Figure out the number of possible node ids.
init_unavailable_mem(); // todo 似乎一些边边角角的东西 !
// 确定各种边界之后,然后对于每一个nid 进行调用
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
free_area_init_node(nid, NULL,
find_min_pfn_for_node(nid), NULL); // 关键内容
/* Any memory on that node */
if (pgdat->node_present_pages)
node_set_state(nid, N_MEMORY);
check_for_memory(pgdat, nid);
}
}
- find_min_pfn_with_active_regions
@todo 注释清晰,但是可以游玩一下 ! ```c /**
- find_min_pfn_with_active_regions - Find the minimum PFN registered *
- Return: the minimum PFN based on information provided via
- memblock_set_node(). */ unsigned long __init find_min_pfn_with_active_regions(void) { return find_min_pfn_for_node(MAX_NUMNODES); }
/* Find the lowest pfn for a node */ static unsigned long __init find_min_pfn_for_node(int nid) { unsigned long min_pfn = ULONG_MAX; unsigned long start_pfn; int i;
for_each_mem_pfn_range(i, nid, &start_pfn, NULL, NULL)
min_pfn = min(min_pfn, start_pfn);
if (min_pfn == ULONG_MAX) {
pr_warn("Could not find start_pfn for node %d\n", nid);
return 0;
}
return min_pfn; } ```
free_area_init_node
- zones_size 和 zholes_size 都是 NULL,当首次从 free_area_init_nodes 的时候,两者仅仅被 calculate_node_totalpages 而已
- 之后从 numa 的位置会被再次调用一次。
void __init free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn,
unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->kswapd_classzone_idx);
pgdat->node_id = nid;
pgdat->node_start_pfn = node_start_pfn;
pgdat->per_cpu_nodestats = NULL;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
pr_info("Initmem setup node %d [mem %#018Lx-%#018Lx]\n", nid,
(u64)start_pfn << PAGE_SHIFT,
end_pfn ? ((u64)end_pfn << PAGE_SHIFT) - 1 : 0);
#else
start_pfn = node_start_pfn;
#endif
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
alloc_node_mem_map(pgdat); // NULL
pgdat_set_deferred_range(pgdat); // NULL
free_area_init_core(pgdat);
}
// 原来这就是 zone 的各种大小的初始化的位置啊 !
static void __init calculate_node_totalpages(struct pglist_data *pgdat,
unsigned long node_start_pfn,
unsigned long node_end_pfn,
unsigned long *zones_size,
unsigned long *zholes_size)
{
unsigned long realtotalpages = 0, totalpages = 0;
enum zone_type i;
for (i = 0; i < MAX_NR_ZONES; i++) {
struct zone *zone = pgdat->node_zones + i;
unsigned long zone_start_pfn, zone_end_pfn;
unsigned long size, real_size;
size = zone_spanned_pages_in_node(pgdat->node_id, i,
node_start_pfn,
node_end_pfn,
&zone_start_pfn,
&zone_end_pfn,
zones_size); // todo
real_size = size - zone_absent_pages_in_node(pgdat->node_id, i,
node_start_pfn, node_end_pfn,
zholes_size); // todo
if (size)
zone->zone_start_pfn = zone_start_pfn;
else
zone->zone_start_pfn = 0;
zone->spanned_pages = size;
zone->present_pages = real_size;
totalpages += size;
realtotalpages += real_size;
}
pgdat->node_spanned_pages = totalpages;
pgdat->node_present_pages = realtotalpages;
printk(KERN_DEBUG "On node %d totalpages: %lu\n", pgdat->node_id,
realtotalpages);
}
free_area_init_core
/*
* Set up the zone data structures:
* - mark all pages reserved
* - mark all memory queues empty
* - clear the memory bitmaps
*
* NOTE: pgdat should get zeroed by caller.
* NOTE: this function is only called during early init.
*/
static void __init free_area_init_core(struct pglist_data *pgdat)
{
enum zone_type j;
int nid = pgdat->node_id;
pgdat_init_internals(pgdat); // pgdat 中间的各种 lock waitqueue 的初始化
pgdat->per_cpu_nodestats = &boot_nodestats; // todo 这是啥 ?
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, freesize, memmap_pages;
unsigned long zone_start_pfn = zone->zone_start_pfn; // 这说明,之前 zone 就初始化好了 !
size = zone->spanned_pages;
freesize = zone->present_pages;
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, freesize); // 计算用于 memmap 的 pages
if (!is_highmem_idx(j)) {
if (freesize >= memmap_pages) {
freesize -= memmap_pages;
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
pr_warn(" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
}
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;
nr_all_pages += freesize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone_init_internals(zone, j, nid, freesize); // zone 的基本内容的初始化
if (!size)
continue;
set_pageblock_order(); // 空
setup_usemap(pgdat, zone, zone_start_pfn, size); // 空
init_currently_empty_zone(zone, zone_start_pfn, size); // 初始化 zone 上的 buddy allocator ,但是数据目前还没有装入
memmap_init(size, nid, j, zone_start_pfn); // 将负责的区间的 page struct 初始化,将负责的 pageblock 标记为 MIGRATE_MOVABLE
}
}
void __meminit init_currently_empty_zone(struct zone *zone,
unsigned long zone_start_pfn,
unsigned long size)
{
struct pglist_data *pgdat = zone->zone_pgdat;
int zone_idx = zone_idx(zone) + 1;
if (zone_idx > pgdat->nr_zones)
pgdat->nr_zones = zone_idx;
zone->zone_start_pfn = zone_start_pfn; // calculate_node_totalpages 中间计算出来的 !
zone_init_free_lists(zone);
zone->initialized = 1;
}
static void __meminit zone_init_free_lists(struct zone *zone)
{
unsigned int order, t;
for_each_migratetype_order(order, t) {
INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);
zone->free_area[order].nr_free = 0;
}
}
void __meminit __weak memmap_init(unsigned long size, int nid,
unsigned long zone, unsigned long start_pfn)
{
memmap_init_zone(size, nid, zone, start_pfn, MEMMAP_EARLY, NULL);
}
/*
* Initially all pages are reserved - free ones are freed
* up by memblock_free_all() once the early boot process is
* done. Non-atomic initialization, single-pass.
*/
void __meminit memmap_init_zone(unsigned long size, int nid, unsigned long zone,
unsigned long start_pfn, enum memmap_context context,
struct vmem_altmap *altmap)
{
unsigned long pfn, end_pfn = start_pfn + size;
struct page *page;
if (highest_memmap_pfn < end_pfn - 1)
highest_memmap_pfn = end_pfn - 1;
for (pfn = start_pfn; pfn < end_pfn; ) {
/*
* There can be holes in boot-time mem_map[]s handed to this
* function. They do not exist on hotplugged memory.
*/
if (context == MEMMAP_EARLY) {
if (!early_pfn_valid(pfn)) {
pfn = next_pfn(pfn);
continue;
}
if (!early_pfn_in_nid(pfn, nid)) {
pfn++;
continue;
}
if (overlap_memmap_init(zone, &pfn))
continue;
}
page = pfn_to_page(pfn);
__init_single_page(page, pfn, zone, nid); // page 的各种初始化,其中包括将 nid 和 zone 放到 page 的 flags 中间去
if (context == MEMMAP_HOTPLUG)
__SetPageReserved(page);
/*
* Mark the block movable so that blocks are reserved for
* movable at startup. This will force kernel allocations
* to reserve their blocks rather than leaking throughout
* the address space during boot when many long-lived
* kernel allocations are made.
*
* bitmap is created for zone's valid pfn range. but memmap
* can be created for invalid pages (for alignment)
* check here not to call set_pageblock_migratetype() against
* pfn out of zone.
*/
if (!(pfn & (pageblock_nr_pages - 1))) { // 对于 pageblock_nr_pages 对其 page 做一个代表去设置 pageblock flags,似乎书上说过,开始的时候就是所有都是设置为 MOVABLE 的
set_pageblock_migratetype(page, MIGRATE_MOVABLE);
cond_resched();
}
pfn++;
}
}
zone_init_free_lists : buddy allocator 首次初始化
- 基本的初始化,所有的内容全部初始化为 0 而已,这个函数的调用还是在 setup_arch 中间而已。想要真正的初始化,需要等到 memblock 的 free
- @todo 那么,zone 中间的内存含有空洞,如果处理 ?
static void __meminit zone_init_free_lists(struct zone *zone)
{
unsigned int order, t;
for_each_migratetype_order(order, t) {
INIT_LIST_HEAD(&zone->free_area[order].free_list[t]);
zone->free_area[order].nr_free = 0;
}
}
#define for_each_migratetype_order(order, type) \
for (order = 0; order < MAX_ORDER; order++) \
for (type = 0; type < MIGRATE_TYPES; type++)
build_zonelists
- zonelists 的作用是 ?
x86_64_start_kernel
x86_64_start_reservations
start_kernel
build_all_zonelists
__build_all_zonelists
build_zonelists
build_zonelists_in_node_order
/*
* unless system_state == SYSTEM_BOOTING.
*
* __ref due to call of __init annotated helper build_all_zonelists_init
* [protected by SYSTEM_BOOTING].
*/
void __ref build_all_zonelists(pg_data_t *pgdat)
{
if (system_state == SYSTEM_BOOTING) {
build_all_zonelists_init();
} else {
__build_all_zonelists(pgdat);
/* cpuset refresh routine should be here */
}
vm_total_pages = nr_free_pagecache_pages(); // todo
/*
* Disable grouping by mobility if the number of pages in the
* system is too low to allow the mechanism to work. It would be
* more accurate, but expensive to check per-zone. This check is
* made on memory-hotadd so a system can start with mobility
* disabled and enable it later
*/
if (vm_total_pages < (pageblock_nr_pages * MIGRATE_TYPES))
page_group_by_mobility_disabled = 1;
else
page_group_by_mobility_disabled = 0;
pr_info("Built %u zonelists, mobility grouping %s. Total pages: %ld\n",
nr_online_nodes,
page_group_by_mobility_disabled ? "off" : "on",
vm_total_pages);
#ifdef CONFIG_NUMA
pr_info("Policy zone: %s\n", zone_names[policy_zone]);
#endif
}
static noinline void __init
build_all_zonelists_init(void)
{
int cpu;
__build_all_zonelists(NULL);
/*
* Initialize the boot_pagesets that are going to be used
* for bootstrapping processors. The real pagesets for
* each zone will be allocated later when the per cpu
* allocator is available.
*
* boot_pagesets are used also for bootstrapping offline
* cpus if the system is already booted because the pagesets
* are needed to initialize allocators on a specific cpu too.
* F.e. the percpu allocator needs the page allocator which
* needs the percpu allocator in order to allocate its pagesets
* (a chicken-egg dilemma).
*/
for_each_possible_cpu(cpu)
setup_pageset(&per_cpu(boot_pageset, cpu), 0);
mminit_verify_zonelist(); // todo
cpuset_init_current_mems_allowed(); // todo
}
static void __build_all_zonelists(void *data) // 从上面看,这一个参数就是 NULL
{
int nid;
int __maybe_unused cpu;
pg_data_t *self = data;
static DEFINE_SPINLOCK(lock);
spin_lock(&lock);
#ifdef CONFIG_NUMA
memset(node_load, 0, sizeof(node_load));
#endif
for_each_online_node(nid) {
pg_data_t *pgdat = NODE_DATA(nid);
build_zonelists(pgdat);
}
spin_unlock(&lock);
}
build_zonelists : 当一个 zone 中间的内存不够,那么从哪里找
/*
* Build zonelists ordered by zone and nodes within zones.
* This results in conserving DMA zone[s] until all Normal memory is
* exhausted, but results in overflowing to remote node while memory
* may still exist in local DMA zone.
*/
// 通过 zonelist 可以实现当 Normal memory 没有可用的情况下才会访问 DMA 的内容
// todo results in overflowing to remote node while memory may still exist in local DMA zone. 这是一定的,还是有一些原因 ?
static void build_zonelists(pg_data_t *pgdat)
{
static int node_order[MAX_NUMNODES];
int node, load, nr_nodes = 0;
nodemask_t used_mask;
int local_node, prev_node;
/* NUMA-aware ordering of nodes */
local_node = pgdat->node_id;
load = nr_online_nodes;
prev_node = local_node;
nodes_clear(used_mask);
memset(node_order, 0, sizeof(node_order));
while ((node = find_next_best_node(local_node, &used_mask)) >= 0) {
/*
* We don't want to pressure a particular node.
* So adding penalty to the first node in same
* distance group to make it round-robin.
*/
if (node_distance(local_node, node) !=
node_distance(local_node, prev_node)) // todo 首先理解 find_next_best_node
node_load[node] = load; // 被 find_next_best_node 唯一使用,在 __build_all_zonelists 中间初始化为 0
node_order[nr_nodes++] = node; // 对于该 node 而言,其效果是 ?
prev_node = node;
load--;
}
build_zonelists_in_node_order(pgdat, node_order, nr_nodes); // 添加所有的 node
build_thisnode_zonelists(pgdat); // 只添加自己 node
}
/**
* find_next_best_node - find the next node that should appear in a given node's fallback list
* @node: node whose fallback list we're appending
* @used_node_mask: nodemask_t of already used nodes
*
* We use a number of factors to determine which is the next node that should
* appear on a given node's fallback list. The node should not have appeared
* already in @node's fallback list, and it should be the next closest node
* according to the distance array (which contains arbitrary distance values
* from each node to each node in the system), and should also prefer nodes
* with no CPUs, since presumably they'll have very little allocation pressure
* on them otherwise.
*
* Return: node id of the found node or %NUMA_NO_NODE if no node is found.
*/
static int find_next_best_node(int node, nodemask_t *used_node_mask) // todo 注释很清新,可以分析一下
{
int n, val;
int min_val = INT_MAX;
int best_node = NUMA_NO_NODE;
const struct cpumask *tmp = cpumask_of_node(0);
/* Use the local node if we haven't already */
if (!node_isset(node, *used_node_mask)) {
node_set(node, *used_node_mask);
return node;
}
for_each_node_state(n, N_MEMORY) { // todo 理解这个 macro
/* Don't want a node to appear more than once */
if (node_isset(n, *used_node_mask))
continue;
/* Use the distance array to find the distance */
val = node_distance(node, n);
/* Penalize nodes under us ("prefer the next node") */
val += (n < node);
/* Give preference to headless and unused nodes */
tmp = cpumask_of_node(n);
if (!cpumask_empty(tmp))
val += PENALTY_FOR_NODE_WITH_CPUS;
/* Slight preference for less loaded node */
val *= (MAX_NODE_LOAD*MAX_NUMNODES);
val += node_load[n];
if (val < min_val) {
min_val = val;
best_node = n;
}
}
if (best_node >= 0)
node_set(best_node, *used_node_mask);
return best_node;
}
/*
* Build zonelists ordered by node and zones within node.
* This results in maximum locality--normal zone overflows into local
* DMA zone, if any--but risks exhausting DMA zone.
*/
static void build_zonelists_in_node_order(pg_data_t *pgdat, int *node_order, // 建立 pg_data_t 的 zonelists
unsigned nr_nodes)
{
struct zoneref *zonerefs;
int i;
zonerefs = pgdat->node_zonelists[ZONELIST_FALLBACK]._zonerefs;
for (i = 0; i < nr_nodes; i++) {
int nr_zones;
pg_data_t *node = NODE_DATA(node_order[i]);
nr_zones = build_zonerefs_node(node, zonerefs); // 将 node 负责的含有 page 的 zone 从下向上逐个放到其中
zonerefs += nr_zones;
}
zonerefs->zone = NULL;
zonerefs->zone_idx = 0;
}
/*
* Build gfp_thisnode zonelists
*/
static void build_thisnode_zonelists(pg_data_t *pgdat)
{
struct zoneref *zonerefs;
int nr_zones;
zonerefs = pgdat->node_zonelists[ZONELIST_NOFALLBACK]._zonerefs;
nr_zones = build_zonerefs_node(pgdat, zonerefs);
zonerefs += nr_zones;
zonerefs->zone = NULL;
zonerefs->zone_idx = 0;
}
setup_pageset : 大失所望,还是不知道 pcp 的作用是什么
struct per_cpu_pages {
int count; /* number of pages in the list */
int high; /* high watermark, emptying needed */
int batch; /* chunk size for buddy add/remove */
/* Lists of pages, one per migrate type stored on the pcp-lists */
struct list_head lists[MIGRATE_PCPTYPES];
};
struct per_cpu_pageset {
struct per_cpu_pages pcp; // 核心 + 刷新控制 ?
#ifdef CONFIG_NUMA
s8 expire;
u16 vm_numa_stat_diff[NR_VM_NUMA_STAT_ITEMS];
#endif
#ifdef CONFIG_SMP
s8 stat_threshold;
s8 vm_stat_diff[NR_VM_ZONE_STAT_ITEMS];
#endif
static void setup_pageset(struct per_cpu_pageset *p, unsigned long batch) // p 是某一个cpu 的 per_cpu_pageset, batch = 0
{
pageset_init(p); // easy,将所有的链表初始化,所有变量设置为 0
pageset_set_batch(p, batch); // easy, 将 p 的 batch 和 high 进行赋值
}
free_unref_page_list && free_unref_page : vmscan.c swap.c 的最爱
无非就是将 page free 给 pcp,是在无法理解为什么就变成了 free_unref_page 了
- 提供的两个接口
```c
/*
- Free a 0-order page */ void free_unref_page(struct page *page) { unsigned long flags; unsigned long pfn = page_to_pfn(page);
if (!free_unref_page_prepare(page, pfn)) return;
local_irq_save(flags); // todo irq free_unref_page_commit(page, pfn); local_irq_restore(flags); }
/*
-
Free a list of 0-order pages */ void free_unref_page_list(struct list_head *list) // todo 和 free_unref_page 可以做映射 { struct page *page, *next; unsigned long flags, pfn; int batch_count = 0;
/* Prepare pages for freeing */ list_for_each_entry_safe(page, next, list, lru) { pfn = page_to_pfn(page); if (!free_unref_page_prepare(page, pfn)) list_del(&page->lru); set_page_private(page, pfn); }
local_irq_save(flags); list_for_each_entry_safe(page, next, list, lru) { unsigned long pfn = page_private(page);
set_page_private(page, 0); trace_mm_page_free_batched(page); free_unref_page_commit(page, pfn); /* * Guard against excessive IRQ disabled times when we get * a large list of pages to free. */ if (++batch_count == SWAP_CLUSTER_MAX) { // local_irq_restore(flags); batch_count = 0; local_irq_save(flags); } } local_irq_restore(flags); } ```
-
prepare 和 commit ```c static bool free_unref_page_prepare(struct page *page, unsigned long pfn) { int migratetype;
if (!free_pcp_prepare(page)) return false;
migratetype = get_pfnblock_migratetype(page, pfn); // 将 page 所在的 migratetype 设置为 page 的 migratetype todo 感觉非常的不科学 set_pcppage_migratetype(page, migratetype); return true; }
static void free_unref_page_commit(struct page *page, unsigned long pfn) // 释放单个 page 总是会将其 page 释放给 pcp { struct zone *zone = page_zone(page); struct per_cpu_pages *pcp; int migratetype;
migratetype = get_pcppage_migratetype(page);
__count_vm_event(PGFREE);
/*
* We only track unmovable, reclaimable and movable on pcp lists.
* Free ISOLATE pages back to the allocator because they are being
* offlined but treat HIGHATOMIC as movable pages so we can get those
* areas back if necessary. Otherwise, we may have to free
* excessively into the page allocator
*/
if (migratetype >= MIGRATE_PCPTYPES) { // 考虑到 CONFIG_CMA 和 CONFIG_MEMORY_ISOLATION 没有被配置,下面的判断总是失败
if (unlikely(is_migrate_isolate(migratetype))) {
free_one_page(zone, page, pfn, 0, migratetype);
return;
}
migratetype = MIGRATE_MOVABLE;
}
pcp = &this_cpu_ptr(zone->pageset)->pcp;
list_add(&page->lru, &pcp->lists[migratetype]);
pcp->count++;
if (pcp->count >= pcp->high) {
unsigned long batch = READ_ONCE(pcp->batch);
free_pcppages_bulk(zone, batch, pcp);
} } ```
- 细节的分析
```c
/*
- With DEBUG_VM disabled, order-0 pages being freed are checked only when
- moving from pcp lists to free list in order to reduce overhead. With
- debug_pagealloc enabled, they are checked also immediately when being freed
- to the pcp lists. */ static bool free_pcp_prepare(struct page *page) { if (debug_pagealloc_enabled_static()) return free_pages_prepare(page, 0, true); else return free_pages_prepare(page, 0, false); // DEBUG_VM disable 的情况 }
// 本来这个函数长的一匹,但是几乎由于默认选项的关闭,所以,最后几乎没有什么东西了 static __always_inline bool free_pages_prepare(struct page *page, unsigned int order, bool check_free) { int bad = 0;
if (PageMappingFlags(page)) // 如果指向的不是 address_space ,那么清理掉
page->mapping = NULL;
page->flags &= ~PAGE_FLAGS_CHECK_AT_PREP; // 将该标志清理掉,但是什么时候添加的 ?
return true; } ```
warn_alloc
内核中的程序也无法分配到内存,一般是不太可能的,应该所有的用户态程序先被干掉才对
sfs_client: page allocation failure: order:0, mode:0x480020(GFP_ATOMIC), nodemask=(null),cpuset=f98f2babc627f2be5b0aebd0f3889dccea874b3823e7c555821abfe3c09d4fcc,mems_allowed=0
CPU: 1 PID: 98973 Comm: sfs_client Kdump: loaded Tainted: G X --------- - - 4.18.0-513.24.1.el8_9.v1.aarch64 #1
Call trace:
dump_backtrace+0x0/0x178
show_stack+0x28/0x38
dump_stack+0x68/0x8c
warn_alloc+0x10c/0x190
__alloc_pages_nodemask+0xdc4/0xe28
alloc_pages_current+0x9c/0x148
skb_page_frag_refill+0x84/0xd0
try_fill_recv+0x28c/0x4d0 [virtio_net]
virtnet_poll+0x35c/0x498 [virtio_net]
__napi_poll+0x48/0x1c0
net_rx_action+0x2bc/0x340
__do_softirq+0x128/0x338
irq_exit_rcu+0x11c/0x128
irq_exit+0x18/0x28
__handle_domain_irq+0x74/0xc8
gic_handle_irq+0x1a8/0x2e4
call_on_irq_stack+0x28/0x34
do_interrupt_handler+0x48/0x68
el1_interrupt+0x2c/0x40
el1h_64_irq_handler+0x14/0x20
el1h_64_irq+0x84/0x88
vfs_write+0x9c/0x1b8
ksys_write+0x70/0xd8
__arm64_sys_write+0x28/0x38
do_el0_svc+0xa4/0x190
el0_svc+0x2c/0x90
el0t_64_sync_handler+0x88/0xb0
el0t_64_sync+0x148/0x14c
Mem-Info:
active_anon:268 inactive_anon:100687 isolated_anon:0#012 active_file:5369 inactive_file:4300 isolated_file:0#012 unevictable:261 dirty:286 writeback:43#012 slab_reclaimable:1138 slab_unreclaimable:2316#012 mapped:7086 shmem:439 pagetables:512 bounce:0#012 free:7410 free_pcp:108 free_cma:0
Node 0 active_anon:17152kB inactive_anon:6443968kB active_file:328896kB inactive_file:269184kB unevictable:16704kB isolated(anon):0kB isolated(file):0kB mapped:453504kB dirty:7296kB writeback:13760kB shmem:28096kB shmem_thp: 0kB shmem_pmdmapped: 0kB anon_thp: 0kB writeback_tmp:0kB kernel_stack:50432kB pagetables:32768kB all_unreclaimable? no
Node 0 DMA32 free:254784kB min:528320kB low:531200kB high:534080kB active_anon:1088kB inactive_anon:2551680kB active_file:32704kB inactive_file:45440kB unevictable:0kB writepending:9408kB present:3145728kB managed:2900352kB mlocked:0kB bounce:0kB free_pcp:3904kB local_pcp:1216kB free_cma:0kB
lowmem_reserve[]: 0 316 316
Node 0 Normal free:272064kB min:531520kB low:536640kB high:541760kB active_anon:16064kB inactive_anon:3892288kB active_file:264256kB inactive_file:223936kB unevictable:16704kB writepending:12096kB present:5242880kB managed:5223616kB mlocked:13632kB bounce:0kB free_pcp:3072kB local_pcp:128kB free_cma:0kB
lowmem_reserve[]: 0 0 0
Node 0 DMA32: 1042*64kB (UM) 581*128kB (UM) 246*256kB (UM) 58*512kB (UM) 12*1024kB (UM) 1*2048kB (U) 2*4096kB (U) 0*8192kB 0*16384kB 0*32768kB 0*65536kB 0*131072kB 0*262144kB 0*524288kB = 256256kB
Node 0 Normal: 1214*64kB (UM) 82*128kB (UM) 6*256kB (U) 77*512kB (U) 53*1024kB (U) 21*2048kB (U) 7*4096kB (U) 2*8192kB (U) 0*16384kB 0*32768kB 0*65536kB 0*131072kB 0*262144kB 0*524288kB = 271488kB
Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=16777216kB
Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=524288kB
Node 0 hugepages_total=0 hugepages_free=0 hugepages_surp=0 hugepages_size=2048kB
9403 total pagecache pages
0 pages in swap cache
Swap cache stats: add 0, delete 0, find 0/0
Free swap = 0kB
Total swap = 0kB
131072 pages RAM
0 pages HighMem/MovableOnly
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。