Memory Compaction
关键问题
- 谁有需求
- 谁来触发,触发的标准是什么?
关键参考
- https://www.cnblogs.com/LoyenWang/p/11746357.html : 应该是很清楚了
- http://linux.laoqinren.net/kernel/memory-compaction/
观测
cat /proc/vmstat | grep compact
compact_migrate_scanned 21449454859
compact_free_scanned 29007736688
compact_isolated 3223998954
compact_stall 19757
compact_fail 16694
compact_success 3063
compact_daemon_wake 17679
compact_daemon_migrate_scanned 21027824586
compact_daemon_free_scanned 28788825995
/proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 1 1 1 1 1 1 1 0 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 2
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 21 28 35 37 33 25 26 20 14 9 6
Node 0, zone DMA32, type Movable 389 341 328 311 260 233 199 151 94 122 193
Node 0, zone DMA32, type Reclaimable 19 25 57 58 99 103 94 84 62 7 2
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 708 278 229 186 87 101 18 0 1 178 244
Node 0, zone Normal, type Movable 10761 4574 2481 7389 9300 3857 1461 463 463 14 998
Node 0, zone Normal, type Reclaimable 1 131 149 68 25 6 2 26 21 8 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 1 0
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate
Node 0, zone DMA 3 5 0 0 0 0
Node 0, zone DMA32 67 737 88 0 0 0
Node 0, zone Normal 2671 28816 252 1 0 0
在虚拟机的 2 numa 的机器上:
➜ ~ cat /proc/pagetypeinfo
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 0 0 0 0 1 1 1 1 0 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 1 0 0 0 0 0 1 1 1 1 0
Node 0, zone DMA32, type Movable 3 7 6 3 3 5 4 2 4 4 733
Node 0, zone DMA32, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 16 26 2 1 1 1 1 1 1 0 0
Node 0, zone Normal, type Movable 119 46 11 6 4 3 1 1 1 1 2910
Node 0, zone Normal, type Reclaimable 0 1 0 0 1 1 0 0 1 1 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate
Node 0, zone DMA 1 7 0 0 0 0
Node 0, zone DMA32 2 1526 0 0 0 0
Node 0, zone Normal 98 6536 22 0 0 0
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 1, zone Normal, type Unmovable 10 77 148 48 27 5 0 1 0 1 0
Node 1, zone Normal, type Movable 1 1 1 0 0 0 1 0 0 0 3641
Node 1, zone Normal, type Reclaimable 0 0 0 1 0 0 0 0 1 0 0
Node 1, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 1, zone Normal, type CMA 0 0 0 0 0 0 0 0 0 0 0
Node 1, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate
Node 1, zone Normal 96 8084 12 0 0 0
对于每一个 node 中展示如下两个内容:
- pagetypeinfo_showfree_print : 展示 free_list 中每一个 page 的大小,是 /proc/buddyinfo 的详细版本
-
pagetypeinfo_showblockcount_print : 展示 page block 的状态
- 为什么分配那么多大页,让 hugeltb 对于 pageblock 的影响几乎没有啊 ?
- hugetlb 分配的时候
- 这会导致成为问题吗?
/sys/kernel/debug/extfrag
[root@nixos:/sys/kernel/debug/extfrag]# grep "" -r
extfrag_index:Node 0, zone DMA -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000
extfrag_index:Node 0, zone DMA32 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000
extfrag_index:Node 0, zone Normal -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000
unusable_index:Node 0, zone DMA 0.000 0.000 0.000 0.002 0.004 0.010 0.022 0.044 0.090 0.090 0.272
unusable_index:Node 0, zone DMA32 0.000 0.001 0.003 0.007 0.015 0.031 0.060 0.111 0.194 0.303 0.481
unusable_index:Node 0, zone Normal 0.000 0.001 0.004 0.009 0.040 0.115 0.177 0.225 0.256 0.317 0.367
控制
/proc/sys/vm/compact_memory
/proc/sys/vm/compaction_proactiveness
20
影响 fragmentation_score_wmark(), 其调用路径为:
- compact_zone -> compact_finished-> __compact_finished()
- kcompactd -> should_proactive_compact_node()
/proc/sys/vm/extfrag_threshold
500
compaction_suitable 中使用,该函数是分析一个 zone 的中内存 到底是不够还是碎片话过于严重。
/proc/sys/vm/compact_unevictable_allowed
1
有点细致,默认为 true, 可以调整的。
- hugetlb 的这种大页是不是 unevictable 的 ?
/sys/devices/system/node/node0/compact
为什么需要构建出来这种明显的不一致?
[ ] 还是使用 kernel 的 unittest 先感受一下吧
[x] 分配的页是什么 migrate 类型
在函数 prepare_alloc_pages 中:
ac->migratetype = gfp_migratetype(gfp_mask);
通过这两个 flag 来确定的:
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE|__GFP_MOVABLE)
[ ] 如果尝试分配大页,会因为 compaction 而 hang 住吗
不会,看上去会直接失败的,如果不会,什么时候决定放弃
分配大页的时候,page cache 会被清理掉
为什么需要将 page 组织为 page block ?
- 希望获取一个连续区域大小的 free page
- 很多时候是为了分配大页,那么最后这个连续区域是一个大页的大小
- 提前确定那些 page block 范围的页是
/*
* Huge pages are a constant size, but don't exceed the maximum allocation
* granularity.
*/
#define pageblock_order min_t(unsigned int, HUGETLB_PAGE_ORDER, MAX_ORDER)
- 为什么不能超过 MAX_ORDER ? 例如默认大页只是支持 512G 的大小
TODO
- 检查一些过程
- fallback 的过程
- 如果在一个 pageblock 中分配了一个 page,那么是不是需要将这个 pageblock 的属性为什么,是不是需要进行修改
- fallback 的过程
- 如果是 UNMOVABLE 的页面释放了,其会放到那种属性的 buddy 中,如果放到 MOVABLE 中,那么岂不是会导致 buddy 再去分配 UNMOVABLE 的时候, 总是需要 fallback 的吗
-
释放的页进入的 freelist 的移动属性取决于 pageblock
- compaction 只能是 zone 内部的吗? 可以跨 zone 迁移 page 的
- 应该不是
steal 操作
find_suitable_fallback 的两个调用位置:
# 第一种
find_suitable_fallback+1
rmqueue_bulk+1892
get_page_from_freelist+4177
__alloc_pages_direct_compact+493
__alloc_pages_slowpath.constprop.0+1385
__alloc_pages+506
# 第二种
find_suitable_fallback+1
compact_zone+2618
__rmqueue_fallback- find_suitable_fallback : 找到 fallback
- get_page_from_free_area
- steal_suitable_fallback :是不分配了之后一个 page 之后立刻让这个 pageblock 修改属性的。
- 没有这个属性的 page,那么进行 steal ,此时将该 pageblock 剩余的 page 全部处理掉,如果 steal 的 page 比较少,那么并不会去将反转 pageblock 的属性。
-
从什么 pageblock 上释放,那么该 page 的属性就是啥。
- 为什么 compact 的过程中,需要调用 find_suitable_fallback 来实现 fallback 的
基本流程
- compact_zone
- isolate_migratepages :这个是核心了
- isolate_migratepages_block : 对于一个范围中的 page 从 lru 中取出来,其中对于 page 存在很多过滤的操作,例如是 free 的 page,例如不再 LRU 中的 page
- fast_find_migrateblock :首先扫描一下 freelist,从数据比较多的位置开始
- isolate_movable_page :似乎未使用
- del_page_from_lru_list : 最终的行动
- isolate_migratepages_block : 对于一个范围中的 page 从 lru 中取出来,其中对于 page 存在很多过滤的操作,例如是 free 的 page,例如不再 LRU 中的 page
- lru_add_drain_cpu_zone : drain ???
- migrate_pages
- compaction_alloc : 这是传递给 migrate pages 的 hook,这里来获取
- isolate_freepages
__isolate_free_page: 可能会修改 pageblock 的属性
- compaction_alloc : 这是传递给 migrate pages 的 hook,这里来获取
- release_freepages : 释放用不完的 free_pages 的时候吗?
- isolate_migratepages :这个是核心了
@[
compact_zone+895
kcompactd_do_work+372
kcompactd+832
kthread+232
ret_from_fork+34
]: 209
@[
compact_zone+1525
compact_zone_order+187
try_to_compact_pages+238
__alloc_pages_direct_compact+140
__alloc_pages_slowpath.constprop.0+514
__alloc_pages+506
alloc_buddy_huge_page.isra.0+67
alloc_fresh_huge_page+399
alloc_pool_huge_page+109
set_max_huge_pages+371
hugetlb_sysctl_handler_common+252
proc_sys_call_handler+408
new_sync_write+265
vfs_write+521
ksys_write+95
do_syscall_64+59
entry_SYSCALL_64_after_hwframe+68
]: 485210
__rmqueue_fallback:是进行类型 fallback 的时候
find_suitable_fallback
- compact_zone
- find_suitable_fallback
The hard work behind large physical memory allocations in the kernel
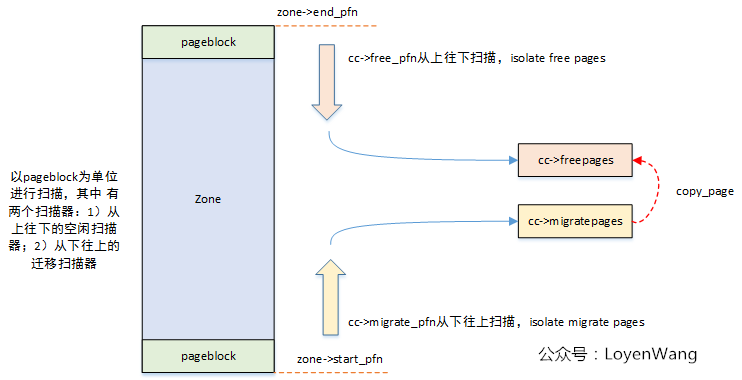
- Migration scanner looks for migration source pages ‒ Starts at beginning (first page) of a zone, moves towards end ‒ Isolates movable pages from their LRU lists
-
Free scanner looks for migration target pages ‒ Starts at the end of zone, moves towards beginning ‒ Isolates free pages from buddy allocator (splits as needed)
- Free page goes to UNMOVABLE free listas the pageblock is UNMOVABLE.
free list 中间显然挂的是 page 而不是 page block
- UNMOVABLE allocation steals all free pages from the pageblock (too few to also “repaint” the pageblock) and grabs the smallest
对应的代码:
- steal_suitable_fallback
- move_freepages_block :将这个 page 所在的所有的 page 全部 steal
- set_pageblock_migratetype :如果可以全部 steal,那么也会修改 pageblock 的迁移属性
如果 free list 中间含有 migrate type,同时 page block 持有 migrate type ,没有冲突吗?
- free list 的选择被 GFP 的确定
- pageblock 应该是在扫描 isolate 的时候使用,当一个 page 处于被 use 的状态,其 mobility 被所处的 page block 确定
TODO 反向 fallback 除非表示为 steal 整个 page block 的,page block 让扫描变的简单,但是 reclaimable 中间放置一个 movable, 感觉也确定当前的 page in use or not 也不是很好判断 !
Short topics in memory management
So, this time around, Mel has posted two sets of patches: a list-based grouping mechanism and a new ZONE_MOVABLE zone which is restricted to movable allocations.
将类似的放到 list 上或者 zone 上,但是其中的工作 ?
Avoiding - and fixing - memory fragmentation
But there are a few situations where physically-contiguous memory is absolutely required.
- These include large kernel data structures (except those created with vmalloc())
- and any memory which must appear contiguous to peripheral devices.
- DMA buffers for low-end devices (those which cannot do scatter/gather I/O) are a classic example.
- If a large (“high order”) block of memory is not available when needed, something will fail and yet another user will start to consider switching to BSD.
So, in this patch, movable pages (those marked with __GFP_MOVABLE) are generally those belonging to user-space processes.
Moving a user-space page is just a matter of copying the data and changing the page table entry, so it is a relatively easy thing to do.
Reclaimable pages (__GFP_RECLAIMABLE), instead, usually belong to the kernel.
They are either allocations which are expected to be short-lived (some kinds of DMA buffers, for example, which only exist for the duration of an I/O operation)
or can be discarded if needed (various types of caches). Everything else is expected to be hard to reclaim.
- 用户数据可以随便移动,copy 数据然后修改 pte 即可。
- 但是内核态的采用的是线性映射,如果将页面进行移动,那么指向其的指针全部需要进行修改,但是很难找到指向其的指针。
- 内核 backing store 的方法 : 将该 page 写回。
migratetype
sudo cat /proc/pagetypeinfo
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*
* The other migratetypes do not have fallbacks.
*/
static int fallbacks[MIGRATE_TYPES][3] = {
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
};
可以观测的内容:
compaction
https://linuxplumbersconf.org/event/2/contributions/65/attachments/15/171/slides-expanded.pdf
- https://www.cnblogs.com/Linux-tech/p/13326565.html
- 请问 isolation 和 compaction 有关联吗 ? 为什么会存在 isolation.c 这个文件啊
- 无论是 page reclaim 还是 compaction 都是内存分配不足,需要采取的措施。非常怀疑,page compaction 和 page reclaim 的代码是对称的 ?
- 工作的范围 : zone
- 触发机制 : daemon + direct 触发
守护进程需要处理的问题在于 :
- 什么时候启动
- 做到什么程度收手
共同的问题:
- 选择那些 page 进行处理
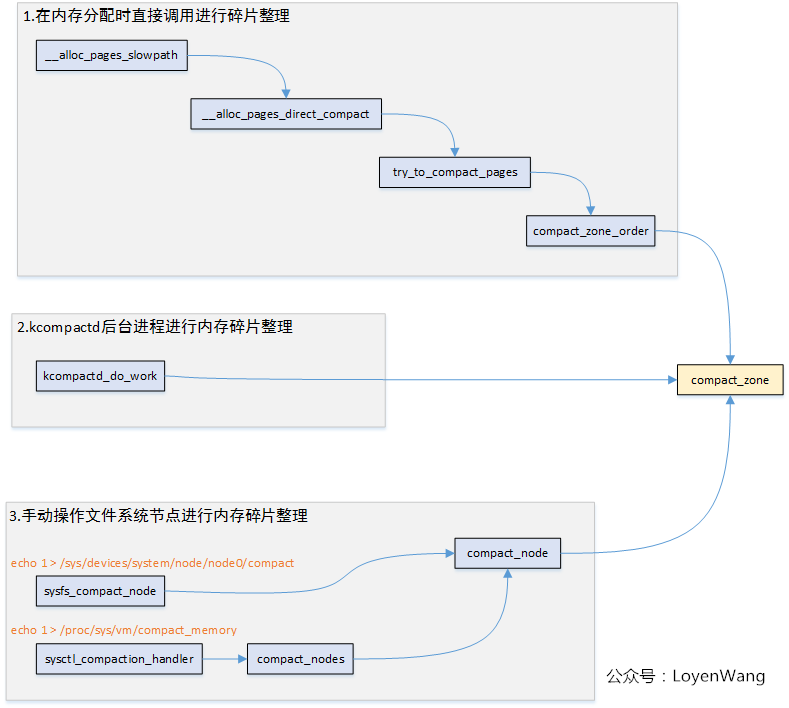
第一种情况 : 直接触发
/**
* try_to_compact_pages - Direct compact to satisfy a high-order allocation
* @gfp_mask: The GFP mask of the current allocation
* @order: The order of the current allocation
* @alloc_flags: The allocation flags of the current allocation
* @ac: The context of current allocation
* @prio: Determines how hard direct compaction should try to succeed
*
* This is the main entry point for direct page compaction.
*/
enum compact_result try_to_compact_pages(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
enum compact_priority prio, struct page **capture)
- try_to_compact_pages : 根据 alloc_context 提供的 zonelist 循环调用 compact_zone_order
- compact_zone_order : 组装 compact_control,然后调用 compact_zone
第二种情况 : 守护进程
/*
* The background compaction daemon, started as a kernel thread
* from the init process.
*/
static int kcompactd(void *p)
共同到达的情况: compact_zone_order 和 kcompactd_do_work 分别是 direct 和 kthread 两种情况,组装 compact_control 和 capture_control 然后调用 compact_zone.
compact_zone 的核心是调用 :
while ((ret = compact_finished(cc)) == COMPACT_CONTINUE) {
// 通过 isolate_migratepages 确定需要搬动的 pages
switch (isolate_migratepages(cc)) {
}
// 将收集到的 cc->migratepages 进行搬迁 cc->freepages 中间去
err = migrate_pages(&cc->migratepages, compaction_alloc,
compaction_free, (unsigned long)cc, cc->mode,
MR_COMPACTION);
}
isolate_migratepages 和 isolate_freepages 存在什么区别 ? 很类似,但是 isolate_freepages 似乎是在 isolate_migratepages 的基础上进行的。 // TODO 无论如何,可以非常清晰的知道,isolate_migratepages 就是 compaction 的核心 // 可以解释 : 到底如何扫描 memblock ,从 memblock 中间找到 free page
- what’s criteria to isolate page ?
alloc_contig_range => __alloc_contig_migrate_range => isolate_migratepages_range => isolate_migratepages_block
in function isolate_migratepages_block(), the answer hides.
memory compaction 就是通过将正在使用的可移动页面迁移到另一个地方以获得连续的空闲页面的方法。针对内存碎片,内核中定义了 migrate_type 用于描述迁移类型:
MIGRATE_UNMOVABLE:不可移动,对应于内核分配的页面;MIGRATE_MOVABLE:可移动,对应于从用户空间分配的内存或文件;MIGRATE_RECLAIMABLE:不可移动,可以进行回收处理;
/*
* Determines how hard direct compaction should try to succeed.
* Lower value means higher priority, analogically to reclaim priority.
*/
enum compact_priority {
COMPACT_PRIO_SYNC_FULL,
MIN_COMPACT_PRIORITY = COMPACT_PRIO_SYNC_FULL,
COMPACT_PRIO_SYNC_LIGHT,
MIN_COMPACT_COSTLY_PRIORITY = COMPACT_PRIO_SYNC_LIGHT,
DEF_COMPACT_PRIORITY = COMPACT_PRIO_SYNC_LIGHT,
COMPACT_PRIO_ASYNC,
INIT_COMPACT_PRIORITY = COMPACT_PRIO_ASYNC
};
本结构用于描述 memory compact 的几种不同方式:
- COMPACT_PRIO_SYNC_FULL/MIN_COMPACT_PRIORITY:最高优先级,压缩和迁移以同步的方式完成;
- COMPACT_PRIO_SYNC_LIGHT/MIN_COMPACT_COSTLY_PRIORITY/DEF_COMPACT_PRIORITY:中优先级,压缩以同步方式处理,迁移以异步方式处理;
- COMPACT_PRIO_ASYNC/INIT_COMPACT_PRIORITY:最低优先级,压缩和迁移以异步方式处理。
/* Return values for compact_zone() and try_to_compact_pages() */
/* When adding new states, please adjust include/trace/events/compaction.h */
enum compact_result {
/* For more detailed tracepoint output - internal to compaction */
COMPACT_NOT_SUITABLE_ZONE,
/*
* compaction didn't start as it was not possible or direct reclaim
* was more suitable
*/
COMPACT_SKIPPED,
/* compaction didn't start as it was deferred due to past failures */
COMPACT_DEFERRED,
/* compaction not active last round */
COMPACT_INACTIVE = COMPACT_DEFERRED,
/* For more detailed tracepoint output - internal to compaction */
COMPACT_NO_SUITABLE_PAGE,
/* compaction should continue to another pageblock */
COMPACT_CONTINUE,
/*
* The full zone was compacted scanned but wasn't successfull to compact
* suitable pages.
*/
COMPACT_COMPLETE,
/*
* direct compaction has scanned part of the zone but wasn't successfull
* to compact suitable pages.
*/
COMPACT_PARTIAL_SKIPPED,
/* compaction terminated prematurely due to lock contentions */
COMPACT_CONTENDED,
/*
* direct compaction terminated after concluding that the allocation
* should now succeed
*/
COMPACT_SUCCESS,
};
- compact_zone and try_to_compact_pages
- compact_zone_order => compact_zone
/*
* MIGRATE_ASYNC means never block
* MIGRATE_SYNC_LIGHT in the current implementation means to allow blocking
* on most operations but not ->writepage as the potential stall time
* is too significant
* MIGRATE_SYNC will block when migrating pages
* MIGRATE_SYNC_NO_COPY will block when migrating pages but will not copy pages
* with the CPU. Instead, page copy happens outside the migratepage()
* callback and is likely using a DMA engine. See migrate_vma() and HMM
* (mm/hmm.c) for users of this mode.
*/
enum migrate_mode {
MIGRATE_ASYNC,
MIGRATE_SYNC_LIGHT,
MIGRATE_SYNC,
MIGRATE_SYNC_NO_COPY,
};
compaction_suitable(): one of caller iscompact_zone, test whether a zone is suitable for compaction, if not, just return.
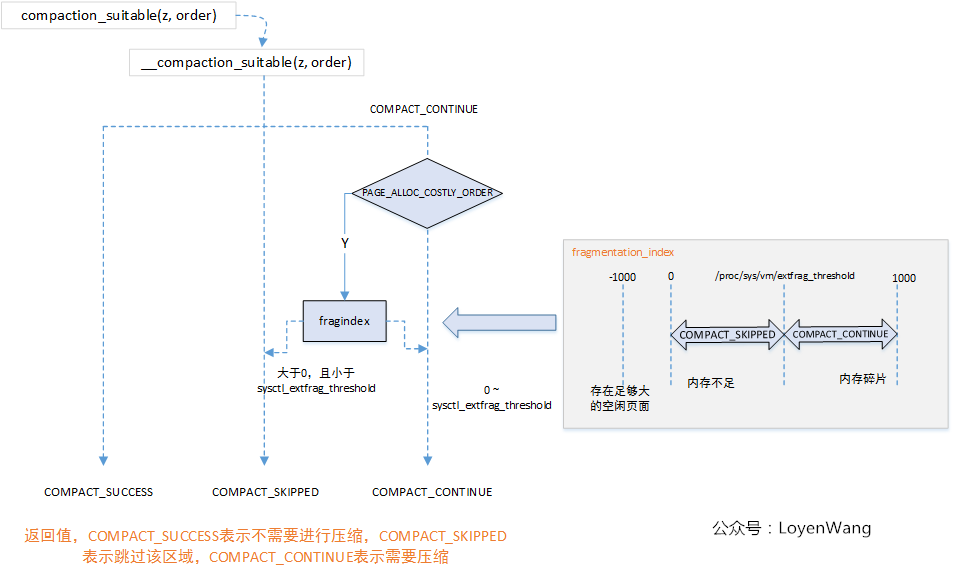
- 除去申请的页面,空闲页面数将低于水印值,或者虽然大于等于水印值,但是没有一个足够大的空闲页块;
- 空闲页面减去两倍的申请页面(两倍表明有足够多的的空闲页面作为迁移目标),高于水印值;
- 申请的 order 大于 PAGE_ALLOC_COSTLY_ORDER 时,计算碎片指数 fragindex,根据值来判断;
- I skip this part, may read it carefully
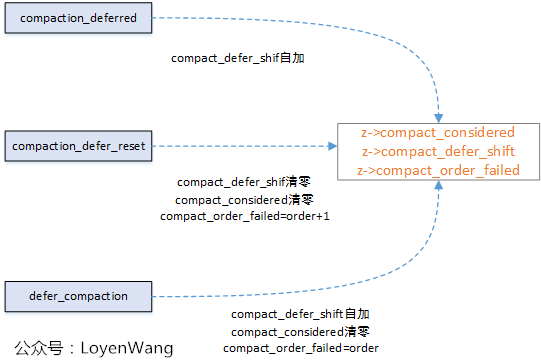
compact deferred
struct zone {
...
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
*/
unsigned int compact_considered; //记录推迟次数
unsigned int compact_defer_shift; //(1 << compact_defer_shift)=推迟次数,最大为6
int compact_order_failed; //记录碎片整理失败时的申请order值
...
};
分析一些细节
- set_pfnblock_flags_mask : 设置整个 page block 的 migrate 状态
- set_pageblock_migratetype : 在 page_alloc.c 中,在分配的时候确定设置何种类型
- 实际上,测试的过程中,跑跑简单的内存分配,根本不会调用
#define PB_migratetype_bits 3
/* Bit indices that affect a whole block of pages */
enum pageblock_bits {
PB_migrate,
PB_migrate_end = PB_migrate + PB_migratetype_bits - 1,
/* 3 bits required for migrate types */
PB_migrate_skip,/* If set the block is skipped by compaction */
/*
* Assume the bits will always align on a word. If this assumption
* changes then get/set pageblock needs updating.
*/
NR_PAGEBLOCK_BITS
};
一个 pageblock 中存在 3 个 bit ,
- 前两个 bit 存储
enum migratetype - 第三个 bit 存储
PB_migrate_skip
[ ] 如果分配的时候,如何尽量将 unmovable 的页放到 unmovable 的 page block 中
[ ] 如何理解 MIGRATE_HIGHATOMIC 以及 pcp lists
搜索一下 pcp list ,就是可以看到 per_cpu_pages 的类型为
enum migratetype {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
[ ] HighAtomic 到底什么是 HighAtomic 类型的
- 如果大量的消耗内存的的时候,为什么这个数量会增加一些?
[ ] 为什么默认初始化的 pageblock 类型为 MIGRATE_MOVABLE 啊
Number of blocks type Unmovable Movable Reclaimable HighAtomic CMA Isolate
Node 0, zone DMA 1 7 0 0 0 0
Node 0, zone DMA32 2 1526 0 0 0 0
Node 0, zone Normal 196 260364 48 0 0 0
而且最奇怪的是,当制作了大量的 pagecache ,只有少量的会转换为 Reclaimable
导致无论在什么环境中,总是几乎全部的内存都是 Reclaimable 的!
一个设计上的考虑
- 假设两个连续的 region ,会为了获得更大的 order ,
存在可能将其合并为
[ movable ]吗?
[ movable ] [ reclaimable ]
什么是 MIGRATE_PCPTYPES
猜测是:
struct per_cpu_zonestat __percpu *pcp = zone->per_cpu_zonestats;
看看这个
https://cn.pingcap.com/blog/linux-kernel-vs-memory-fragmentation-1/
https://mp.weixin.qq.com/s/Ts7yGSuTrh3JLMnP4E3ajA
怀疑 pageblock 的大小就是最大分配的连续的物理内存的大小 !
跟踪这个函数: migrate_pages_batch
用一用 bcc 的 compactsnoop
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。