vm_area_struct::vm_operations_struct 结构体的作用
mmap 映射的一个 fd 之后,在该 vma 上操作的行为取决于 fd 的来源:
- 匿名映射不关联 fd,所以没有
vm_operations_structstatic inline bool vma_is_anonymous(struct vm_area_struct *vma) { return !vma->vm_ops; } - socket 的 mmap 是没有含义的
static const struct vm_operations_struct tcp_vm_ops = { }; - 以 hugetlb_vm_ops 为例
/* * When a new function is introduced to vm_operations_struct and added * to hugetlb_vm_ops, please consider adding the function to shm_vm_ops. * This is because under System V memory model, mappings created via * shmget/shmat with "huge page" specified are backed by hugetlbfs files, * their original vm_ops are overwritten with shm_vm_ops. */ const struct vm_operations_struct hugetlb_vm_ops = { .fault = hugetlb_vm_op_fault, .open = hugetlb_vm_op_open, .close = hugetlb_vm_op_close, .may_split = hugetlb_vm_op_split, .pagesize = hugetlb_vm_op_pagesize, };
mmap
- io uring, mmap 的时候需要传入 MAP_POPULATE 参数,以防止内存被 page fault。
- https://github.com/edsrzf/mmap-go : 我们应该使用类似的方法来实现一个 C 语言版本,在 mmap 区域放置汇编代码
// TODO
- 为什么其中的 file_operations::mmap 和 mmap 的关系是什么 ?
- 找到 pgfault 命中到错误的位置的时候,但是范围外面,并且是如何告知用户的 ? 使用信号机制吗 ?
- 据说其中包含了各种 vma 操纵函数,整理一下
static unsigned long myfs_mmu_get_unmapped_area(struct file *file,
unsigned long addr, unsigned long len, unsigned long pgoff,
unsigned long flags)
{
return current->mm->get_unmapped_area(file, addr, len, pgoff, flags);
}
const struct file_operations ramfs_file_operations = {
.get_unmapped_area = ramfs_mmu_get_unmapped_area, // 不是非常理解啊 !
};
在 do_mmap 中间的各种代码都是非常简单的,但是唯独这一行理解不了:
/* Obtain the address to map to. we verify (or select) it and ensure
* that it represents a valid section of the address space.
*/
addr = get_unmapped_area(file, addr, len, pgoff, flags);
- 在 dune 的分析的时候,通过 mmap 是返回一个地址的,这个地址应该是 guest physical address, 也就是 HVA,无论是系统发送过去,从内核的角度分析,其不在乎是哪个 guest 发送的, guest 发送的时候首先会进入到 host 中间,然后调用 syscall.
-
其实可以在进行 vmcall syscall 的时候,可以首先对于 GVA 到 GVA 之间装换
-
调查一下 mmap 如何返回用户地址的
- check flag of
MAP_HUGETLBstatic void * do_mapping(void *base, unsigned long len) { void *mem; mem = mmap((void *) base, len, PROT_READ | PROT_WRITE, MAP_FIXED | MAP_HUGETLB | MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (mem != (void *) base) { // try again without huge pages mem = mmap((void *) base, len, PROT_READ | PROT_WRITE, MAP_FIXED | MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); if (mem != (void *) base) return NULL; } return mem; } - [ ]
brk
- what’s
[heap]incat /proc/self/maps5587dad41000-5587dad62000 rw-p 00000000 00:00 0 [heap]answer: https://stackoverflow.com/questions/17782536/missing-heap-section-in-proc-pid-maps
- what’s difference of brk and mmap ? So what’s are the simplifications and extra of brk ?
mmap layout
mm_struct::mmap_base- setup_new_exec()
mm_struct::stack_start, discuss it ./mm/stack.md
// --------- -> : just statistics of memory size -------------------
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
atomic64_t pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
// --------- -> : vm flags for all vma, mainly used for mlock -------------------
unsigned long def_flags;
spinlock_t arg_lock; /* protect the below fields */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
- so why we need these start and end ?
arch/x86/mm/mmap.c:arch_pick_mmap_layout
- register get_unmapped_area
mm->get_unmapped_area = arch_get_unmapped_area; - choose from
mmap_baseandmmap_legacy_base
mmap_base is top of mmap.
All right, heap grows up, mmap grows down, and stack grows down, like this.
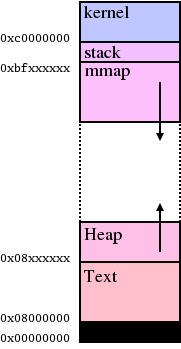
- why I need
mmap_basetoget_unmapped_area()page walk
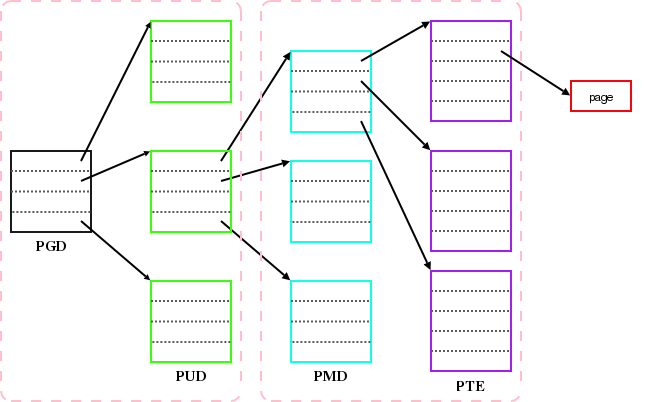
// 总结一下 pagewalk.c 中间的内容 // mincore.c 基本是利用 pagewalk.c 实现的
// TODO 其实存在很多位置走过一遍 page walk,只要需要修改 page table 的需要进行 page walk:
- vmemmap 的填充
- rmap
- gup
check it 这几个概念 : https://stackoverflow.com/questions/8708463/difference-between-kernel-virtual-address-and-kernel-logical-address
还有非常重要的特点,那就是只要设计到 page walk,至少 2000 行
process vm access
// 不同进程地址空间直接拷贝
virtual memory
- 实现地址空间的隔离是虚拟内存的目的,但是,关键位置在于如何实现在隔离的基础上共享和通信。
- 实现隔离的方法: page walk
- 实现共享 : cow + mmap(找到一下使用 mmap 的)
- 不同虚拟内存的属性不同。vma
// ———- 等待处理的事情 —————
- 为什么 mm_struct 中间存在这个,难道这个的实现不是标准操作吗 ?
unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags); - vma_ops : anonymous 的不需要 vm_ops,所以 vm_ops 处理都是文件相关的内容,解释一下每个函数到底如何处理 underlying 的文件的。
- 找到各种 file vma 的插入 vm_ops 的过程是什么 ?
static inline bool vma_is_anonymous(struct vm_area_struct *vma)
{
return !vma->vm_ops;
}
-
虚拟地址空间的结构是什么 ? amd64 的架构上,内核空间如此大,内核空间的线性地址的映射是如何完成的 ?
-
当使用四级的 page walk 的时候,为什么可以实现 48bit 的寻址过程,中间的空洞是如何体现出来的。
-
分析一下经典的函数 :
__pa__va和 kmap 以及 kunmap 的关系是什么 ? 似乎回到 highmem 的内容 -
还是分不清 Kernel Logical Address 和 Kernel Virtual Address 的区别是什么? 这是凭空创建出来混淆人的注意力 // ———- 等待处理的事情 end —————
This hardware feature allows operating systems to map the kernel into the address space of every process and to have very efficient transitions from the user process to the kernel, e.g., for interrupt handling.
- 为什么每一个进程都需要持有内核地址空间 ?
- 似乎 : 反正用户进程无法访问内核地址空间
- interrupt 的时候不用切换地址空间,由于切换地址空间而导致的 TLB flush 都是没有必要使用的。
- fork 会很难实现 : fork 出来的 child 需要从内核态返回,至少在返回到用户层的时候需要使用内核地址空间
- context switch 的过程 : 进入内核态,各种切换(包括切换地址空间),离开内核态。如果用户不包含内核态的地址空间,就需要考虑切换地址空间和进入内核空间,先后 ?,同时 ?
emmmmm fork 和 context switch 的内容需要重新分析
x86_64 规定了虚拟地址空间的 layout[^5]
- 4-level 和 5-level 在 layout 的区分只是 start address 和 length 的区别
- 处于安全问题,这些地址都是加入了随机偏移
- page_offset_base vmalloc_base vmemmap_base 含义清晰
- 其他暂时不管
- 只是 ioremap 的开始位置为什么和 vmalloc_base 使用的位置相同
- cpu_entry_area : https://unix.stackexchange.com/questions/476768/what-is-cpu-entry-area
fork
- fork 的那些 flags 如何控制
- vma 指向的内存如何控制
到底内存中间如何控制其中的
mm_struct
- 并不是所有的进程存在 mm_struct 的, 应该是 kernel thread ?
for_each_process (g) { if(g->mm) pr_debug("%s ---> %lx %lx\n", g->comm, g->mm->mmap_base, g->mm->start_stack); else pr_debug("%s doesn't have mm\n", g->comm); }
mm/mmap.c
似乎 plka 的整个第四章的内容。
问题
- kernel page fault
- 为什么 kernel 会发生 page fault, 不是实现分配好了吗 ?
- file based 和 anon 的区别对照表
- vma_area 的 vm_operations_struct 不同吗 ?
- 创建 vma_area 的方法
- stack 有什么什么需要特殊处理的吗 ?
mmap_pgoff 和 munmap
- 根本的两个 syscall 机制
- munmap 应该是需要调用 rmap 来释放一下相关的内容,但是目前没有找到证据(todo)
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
return ksys_mmap_pgoff(addr, len, prot, flags, fd, pgoff);
}
SYSCALL_DEFINE2(munmap, unsigned long, addr, size_t, len)
{
profile_munmap(addr);
return vm_munmap(addr, len);
}
special mapping 是 vdso 有关的
static const struct vm_operations_struct special_mapping_vmops = {
.close = special_mapping_close,
.fault = special_mapping_fault,
.mremap = special_mapping_mremap,
.name = special_mapping_name,
};
static const struct vm_operations_struct legacy_special_mapping_vmops = {
.close = special_mapping_close,
.fault = special_mapping_fault,
};
reserve 机制
/*
* Initialise sysctl_user_reserve_kbytes.
*
* This is intended to prevent a user from starting a single memory hogging
* process, such that they cannot recover (kill the hog) in OVERCOMMIT_NEVER
* mode.
*
* The default value is min(3% of free memory, 128MB)
* 128MB is enough to recover with sshd/login, bash, and top/kill.
*/
static int init_user_reserve(void)
{
unsigned long free_kbytes;
free_kbytes = global_zone_page_state(NR_FREE_PAGES) << (PAGE_SHIFT - 10);
sysctl_user_reserve_kbytes = min(free_kbytes / 32, 1UL << 17);
return 0;
}
subsys_initcall(init_user_reserve);
overcommit
vm 统计的位置
__vm_enough_memory+1
shmem_alloc_and_acct_folio+341
shmem_getpage_gfp+989
shmem_fallocate+954
vfs_fallocate+328
__x64_sys_fallocate+60
do_syscall_64+56
entry_SYSCALL_64_after_hwframe+99
之后进一步调用 vm_acct_memory 。
核心位置在 : __vm_enough_memory
- OVERCOMMIT_GUESS : 单次分配不能超过 ram + swap 的大小
- OVERCOMMIT_ALWAYS : 不检查
- OVERCOMMIT_NEVER : 虚拟内存不能超过 ram + swap 的大小
vm
主要在 mmap.c 中
问题
- 各种 region 的触发如何管理 ?
- file anon 比对
- brk 实现的方法
- pagefault 实现
mmap 实现细节
- 如何分配内存的 ?
-
mmap 某一个文件之后,然后就可以直接访问,那么 pgfault 如何配合使用 ? https://stackoverflow.com/questions/26259421/use-mmap-in-c-to-write-into-memory
- mmap 处理了 filebased 的 vma,实现 anon 对应的版本 vma 创建管理工作谁来完成 ?
- mmap 之后的操作,对于内存的修改,最后结果会被自动写到文件系统中间吗 ?
- 好像不只是含有 file anon 的 vma !
syscall 的接口汇集到 do_mmap,其中完成各种检查,查找合适的空间 mmap_region 中间实现:
主要,三种情况分别处理。@todo 既然在此处实现三种映射,除非 mmap 不仅仅支持 mmap
最后 vmlink 之类的处理一下:
error = call_mmap(file, vma);
if (error)
goto unmap_and_free_vma;
/* Can addr have changed??
*
* Answer: Yes, several device drivers can do it in their
* f_op->mmap method. -DaveM
* Bug: If addr is changed, prev, rb_link, rb_parent should
* be updated for vma_link()
*/
WARN_ON_ONCE(addr != vma->vm_start);
addr = vma->vm_start;
vm_flags = vma->vm_flags;
} else if (vm_flags & VM_SHARED) {
error = shmem_zero_setup(vma);
if (error)
goto free_vma;
} else {
vma_set_anonymous(vma);
// file based !
static inline int call_mmap(struct file *file, struct vm_area_struct *vma)
{
return file->f_op->mmap(file, vma);
}
int generic_file_mmap(struct file * file, struct vm_area_struct * vma)
{
struct address_space *mapping = file->f_mapping;
if (!mapping->a_ops->readpage)
return -ENOEXEC;
file_accessed(file); // 添加一个文件访问时间而已
vma->vm_ops = &generic_file_vm_ops; // 挂钩上关键的pagefault
return 0;
}
static inline void file_accessed(struct file *file)
{
if (!(file->f_flags & O_NOATIME))
touch_atime(&file->f_path);
}
// shmem based
/**
* shmem_zero_setup - setup a shared anonymous mapping
* @vma: the vma to be mmapped is prepared by do_mmap_pgoff
*/
int shmem_zero_setup(struct vm_area_struct *vma)
{
struct file *file;
loff_t size = vma->vm_end - vma->vm_start;
/*
* Cloning a new file under mmap_sem leads to a lock ordering conflict
* between XFS directory reading and selinux: since this file is only
* accessible to the user through its mapping, use S_PRIVATE flag to
* bypass file security, in the same way as shmem_kernel_file_setup().
*/
file = shmem_kernel_file_setup("dev/zero", size, vma->vm_flags);
if (IS_ERR(file))
return PTR_ERR(file);
if (vma->vm_file)
fput(vma->vm_file);
vma->vm_file = file;
vma->vm_ops = &shmem_vm_ops; // 关键操作
if (IS_ENABLED(CONFIG_TRANSPARENT_HUGE_PAGECACHE) &&
((vma->vm_start + ~HPAGE_PMD_MASK) & HPAGE_PMD_MASK) <
(vma->vm_end & HPAGE_PMD_MASK)) {
khugepaged_enter(vma, vma->vm_flags);
}
return 0;
}
static const struct vm_operations_struct shmem_vm_ops = {
.fault = shmem_fault,
.map_pages = filemap_map_pages,
#ifdef CONFIG_NUMA
.set_policy = shmem_set_policy,
.get_policy = shmem_get_policy,
#endif
};
// anon
static inline void vma_set_anonymous(struct vm_area_struct *vma)
{
vma->vm_ops = NULL; // @todo 猜测这是默认操作方式!
}
猜测之后 vm_fault 会首先通过 pgfault 所在的 vma 中间获取。
@todo 这么说 anon page 是不用处理 page fault 的吗? 显然不是吧 !
mmap 如何给 shmem 和 anon 使用 ? emmmmm 应该是 mmap syscall 和 do_mmap_pgoff 不是等价的, 由于 do_mmap_pgoff 会进一步被其他位置调用,包括 shmem
真正的核心 page fault
检查 ucore : ucore 不区分 anon 和 file , 但是凭什么其可以不区分 ? ucore 没有实现 mmap
// 玩美的配合!
static inline bool vma_is_anonymous(struct vm_area_struct *vma)
{
return !vma->vm_ops;
}
brk 机制
/*
* this is really a simplified "do_mmap". it only handles
* anonymous maps. eventually we may be able to do some
* brk-specific accounting here.
*/
static int do_brk_flags(unsigned long addr, unsigned long len, unsigned long flags, struct list_head *uf)
并没有特别神奇的地方
/* Can we just expand an old private anonymous mapping? */
vma = vma_merge(mm, prev, addr, addr + len, flags,
NULL, NULL, pgoff, NULL, NULL_VM_UFFD_CTX);
if (vma)
goto out;
/*
* create a vma struct for an anonymous mapping
*/
vma = vm_area_alloc(mm);
if (!vma) {
vm_unacct_memory(len >> PAGE_SHIFT);
return -ENOMEM;
}
vma_set_anonymous(vma);
vma->vm_start = addr;
vma->vm_end = addr + len;
vma->vm_pgoff = pgoff;
vma->vm_flags = flags;
vma->vm_page_prot = vm_get_page_prot(flags);
vma_link(mm, vma, prev, rb_link, rb_parent);
out:
@todo 可以分析一下 vma_merge 为什么会失败,难道 heap 不是一个连续的虚拟地址空间吗? 为什么反而可以出现空洞?
vma_merge
- do_brk_flags 调用
- vma_merge 的参数为什么不是两个 vma ,而是一个 prev 和 vma 的各种参数 ?
__vma_adjust
__vma_adjust被 vma_merge 和 vma_adjust 调用static inline int vma_adjust(struct vm_area_struct *vma, unsigned long start, unsigned long end, pgoff_t pgoff, struct vm_area_struct *insert) { return __vma_adjust(vma, start, end, pgoff, insert, NULL); }- 参数 vma insert expand 的含义:
- 被 vma_merge 调用时,参数 insert 总是 NULL
- vma_adjust 在 mmap.c 中间被
__split_vma - 所以,
__vma_adjust函数表示调整 vma 的 start end 和 pgoff,insert 表示调整的时候拆出来的 vma,expand 表示用来 expand 的 vma
- 问题 :
- 参数 vma 和 expand 可能是同一个变量,这对应于什么情况 ? (强行将 vma 展开吗 ?)
/*
* We cannot adjust vm_start, vm_end, vm_pgoff fields of a vma that
* is already present in an i_mmap tree without adjusting the tree.
* The following helper function should be used when such adjustments
* are necessary. The "insert" vma (if any) is to be inserted
* before we drop the necessary locks.
*/
int __vma_adjust(struct vm_area_struct *vma, unsigned long start,
unsigned long end, pgoff_t pgoff, struct vm_area_struct *insert,
struct vm_area_struct *expand)
{
struct mm_struct *mm = vma->vm_mm;
struct vm_area_struct *next = vma->vm_next, *orig_vma = vma;
struct address_space *mapping = NULL;
struct rb_root_cached *root = NULL;
struct anon_vma *anon_vma = NULL;
struct file *file = vma->vm_file;
bool start_changed = false, end_changed = false;
long adjust_next = 0;
int remove_next = 0;
// 合并的情况: 阅读一下 vma_merge 关于 mprotect 带来的影响 todo
if (next && !insert) {
struct vm_area_struct *exporter = NULL, *importer = NULL;
// 考虑自己的边界 和 next 的三个返回
if (end >= next->vm_end) {
/*
* vma expands, overlapping all the next, and
* perhaps the one after too (mprotect case 6).
* The only other cases that gets here are
* case 1, case 7 and case 8.
*/
if (next == expand) {
/*
* The only case where we don't expand "vma"
* and we expand "next" instead is case 8.
*/
VM_WARN_ON(end != next->vm_end);
/*
* remove_next == 3 means we're
* removing "vma" and that to do so we
* swapped "vma" and "next".
*/
remove_next = 3;
VM_WARN_ON(file != next->vm_file);
swap(vma, next);
} else {
VM_WARN_ON(expand != vma);
/*
* case 1, 6, 7, remove_next == 2 is case 6,
* remove_next == 1 is case 1 or 7.
*/
remove_next = 1 + (end > next->vm_end);
VM_WARN_ON(remove_next == 2 &&
end != next->vm_next->vm_end);
VM_WARN_ON(remove_next == 1 &&
end != next->vm_end);
/* trim end to next, for case 6 first pass */
end = next->vm_end;
}
exporter = next;
importer = vma;
/*
* If next doesn't have anon_vma, import from vma after
* next, if the vma overlaps with it.
*/
if (remove_next == 2 && !next->anon_vma)
exporter = next->vm_next;
} else if (end > next->vm_start) {
/*
* vma expands, overlapping part of the next:
* mprotect case 5 shifting the boundary up.
*/
adjust_next = (end - next->vm_start) >> PAGE_SHIFT;
exporter = next;
importer = vma;
VM_WARN_ON(expand != importer);
} else if (end < vma->vm_end) {
/*
* vma shrinks, and !insert tells it's not
* split_vma inserting another: so it must be
* mprotect case 4 shifting the boundary down.
*/
adjust_next = -((vma->vm_end - end) >> PAGE_SHIFT);
exporter = vma;
importer = next;
VM_WARN_ON(expand != importer);
}
// 上面三种情况分析,得到 importer 和 exporter 之后
// importer 表示吸收空间的,exporter 表示释放空间的部分
// 然后进入到 again 中间,开始分析:
/*
* Easily overlooked: when mprotect shifts the boundary,
* make sure the expanding vma has anon_vma set if the
* shrinking vma had, to cover any anon pages imported.
*/
// 当 importer 没有持有 anon_vma 的时候,那么公用一下
// 这里提供了 : anon_vma_clone 的情况不仅仅是 fork
if (exporter && exporter->anon_vma && !importer->anon_vma) {
int error;
importer->anon_vma = exporter->anon_vma;
error = anon_vma_clone(importer, exporter);
if (error)
return error;
}
}
again:
vma_adjust_trans_huge(orig_vma, start, end, adjust_next);
// 对于文件更新应该很简单,但是此处并不是更新的位置
if (file) {
mapping = file->f_mapping;
root = &mapping->i_mmap;
uprobe_munmap(vma, vma->vm_start, vma->vm_end);
if (adjust_next)
uprobe_munmap(next, next->vm_start, next->vm_end);
i_mmap_lock_write(mapping);
if (insert) {
/*
* Put into interval tree now, so instantiated pages
* are visible to arm/parisc __flush_dcache_page
* throughout; but we cannot insert into address
* space until vma start or end is updated.
*/
__vma_link_file(insert);
}
}
// 更新一下 vma 之前,将其从 interval tree 中间删除
// 更新我们需要的三个数值,然后将重新插入
// 对于 mapping->i_mmap 为 NULL 和 非 NULL 都是可以处理的
anon_vma = vma->anon_vma;
if (!anon_vma && adjust_next)
anon_vma = next->anon_vma;
if (anon_vma) {
VM_WARN_ON(adjust_next && next->anon_vma &&
anon_vma != next->anon_vma);
anon_vma_lock_write(anon_vma);
anon_vma_interval_tree_pre_update_vma(vma);
if (adjust_next)
anon_vma_interval_tree_pre_update_vma(next);
}
if (root) {
flush_dcache_mmap_lock(mapping);
vma_interval_tree_remove(vma, root);
if (adjust_next)
vma_interval_tree_remove(next, root);
}
if (start != vma->vm_start) {
vma->vm_start = start;
start_changed = true;
}
if (end != vma->vm_end) {
vma->vm_end = end;
end_changed = true;
}
vma->vm_pgoff = pgoff;
if (adjust_next) {
next->vm_start += adjust_next << PAGE_SHIFT;
next->vm_pgoff += adjust_next;
}
if (root) {
if (adjust_next)
vma_interval_tree_insert(next, root);
vma_interval_tree_insert(vma, root);
flush_dcache_mmap_unlock(mapping);
}
// 如果 next 需要被删除掉
if (remove_next) {
/*
* vma_merge has merged next into vma, and needs
* us to remove next before dropping the locks.
*/
if (remove_next != 3)
__vma_unlink_prev(mm, next, vma);
else
/*
* vma is not before next if they've been
* swapped.
*
* pre-swap() next->vm_start was reduced so
* tell validate_mm_rb to ignore pre-swap()
* "next" (which is stored in post-swap()
* "vma").
*/
__vma_unlink_common(mm, next, NULL, false, vma);
if (file)
__remove_shared_vm_struct(next, file, mapping);
} else if (insert) {
/*
* split_vma has split insert from vma, and needs
* us to insert it before dropping the locks
* (it may either follow vma or precede it).
*/
__insert_vm_struct(mm, insert);
} else {
if (start_changed)
vma_gap_update(vma);
if (end_changed) {
if (!next)
mm->highest_vm_end = vm_end_gap(vma);
else if (!adjust_next)
vma_gap_update(next);
}
}
if (anon_vma) {
anon_vma_interval_tree_post_update_vma(vma);
if (adjust_next)
anon_vma_interval_tree_post_update_vma(next);
anon_vma_unlock_write(anon_vma);
}
// 算是更新结束了吧 !
if (mapping)
i_mmap_unlock_write(mapping);
if (root) {
uprobe_mmap(vma);
if (adjust_next)
uprobe_mmap(next);
}
if (remove_next) {
if (file) {
uprobe_munmap(next, next->vm_start, next->vm_end);
fput(file);
}
if (next->anon_vma)
anon_vma_merge(vma, next);
mm->map_count--;
mpol_put(vma_policy(next));
vm_area_free(next);
/*
* In mprotect's case 6 (see comments on vma_merge),
* we must remove another next too. It would clutter
* up the code too much to do both in one go.
*/
if (remove_next != 3) {
/*
* If "next" was removed and vma->vm_end was
* expanded (up) over it, in turn
* "next->vm_prev->vm_end" changed and the
* "vma->vm_next" gap must be updated.
*/
next = vma->vm_next;
} else {
/*
* For the scope of the comment "next" and
* "vma" considered pre-swap(): if "vma" was
* removed, next->vm_start was expanded (down)
* over it and the "next" gap must be updated.
* Because of the swap() the post-swap() "vma"
* actually points to pre-swap() "next"
* (post-swap() "next" as opposed is now a
* dangling pointer).
*/
next = vma;
}
if (remove_next == 2) {
remove_next = 1;
end = next->vm_end;
goto again;
}
else if (next)
vma_gap_update(next);
else {
/*
* If remove_next == 2 we obviously can't
* reach this path.
*
* If remove_next == 3 we can't reach this
* path because pre-swap() next is always not
* NULL. pre-swap() "next" is not being
* removed and its next->vm_end is not altered
* (and furthermore "end" already matches
* next->vm_end in remove_next == 3).
*
* We reach this only in the remove_next == 1
* case if the "next" vma that was removed was
* the highest vma of the mm. However in such
* case next->vm_end == "end" and the extended
* "vma" has vma->vm_end == next->vm_end so
* mm->highest_vm_end doesn't need any update
* in remove_next == 1 case.
*/
VM_WARN_ON(mm->highest_vm_end != vm_end_gap(vma));
}
}
if (insert && file)
uprobe_mmap(insert);
validate_mm(mm);
return 0;
}
/*
* vma has some anon_vma assigned, and is already inserted on that
* anon_vma's interval trees.
*
* Before updating the vma's vm_start / vm_end / vm_pgoff fields, the
* vma must be removed from the anon_vma's interval trees using
* anon_vma_interval_tree_pre_update_vma().
*
* After the update, the vma will be reinserted using
* anon_vma_interval_tree_post_update_vma().
*
* The entire update must be protected by exclusive mmap_sem and by
* the root anon_vma's mutex.
*/
static inline void
anon_vma_interval_tree_pre_update_vma(struct vm_area_struct *vma)
{
struct anon_vma_chain *avc;
list_for_each_entry(avc, &vma->anon_vma_chain, same_vma)
anon_vma_interval_tree_remove(avc, &avc->anon_vma->rb_root);
}
static inline void
anon_vma_interval_tree_post_update_vma(struct vm_area_struct *vma)
{
struct anon_vma_chain *avc;
list_for_each_entry(avc, &vma->anon_vma_chain, same_vma)
anon_vma_interval_tree_insert(avc, &avc->anon_vma->rb_root);
}
try_to_unmap
/*
* No need to invalidate here it will synchronize on
* against the special swap migration pte.
*/
} else if (PageAnon(page)) {
swp_entry_t entry = { .val = page_private(subpage) };
pte_t swp_pte;
/*
* Store the swap location in the pte.
* See handle_pte_fault() ...
*/
if (unlikely(PageSwapBacked(page) != PageSwapCache(page))) { // 下面的注释说,在 try_to_unmap 的调用路径上,不应该出现这种组合。
/* mm: fix lazyfree BUG_ON check in try_to_unmap_one() */
/* If a page is swapbacked, it means it should be in swapcache in */
/* try_to_unmap_one's path. */
/* If a page is !swapbacked, it mean it shouldn't be in swapcache in */
/* try_to_unmap_one's path. */
/* Check both two cases all at once and if it fails, warn and return */
/* SWAP_FAIL. Such bug never mean we should shut down the kernel. */
WARN_ON_ONCE(1);
ret = false;
/* We have to invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm, address,
address + PAGE_SIZE);
page_vma_mapped_walk_done(&pvmw);
break;
}
// todo PageAnon 为什么可以不是 PageSwapBacked 的,除非 SwapBacked 就是表示在 swap 中间存在
/* MADV_FREE page check */
if (!PageSwapBacked(page)) {
if (!PageDirty(page)) { // todo 猜测此处是那种 VM_SHARED 的那种造成的
/* Invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm,
address, address + PAGE_SIZE);
dec_mm_counter(mm, MM_ANONPAGES);
goto discard;
}
/*
* If the page was redirtied, it cannot be
* discarded. Remap the page to page table.
*/
set_pte_at(mm, address, pvmw.pte, pteval);
SetPageSwapBacked(page);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (swap_duplicate(entry) < 0) { // Verify that a swap entry is valid and increment its swap map count.
set_pte_at(mm, address, pvmw.pte, pteval);
ret = false;
page_vma_mapped_walk_done(&pvmw);
break;
}
if (list_empty(&mm->mmlist)) {
spin_lock(&mmlist_lock);
if (list_empty(&mm->mmlist))
list_add(&mm->mmlist, &init_mm.mmlist); // todo 作用是什么 ?
spin_unlock(&mmlist_lock);
}
dec_mm_counter(mm, MM_ANONPAGES);
inc_mm_counter(mm, MM_SWAPENTS);
swp_pte = swp_entry_to_pte(entry);
if (pte_soft_dirty(pteval))
swp_pte = pte_swp_mksoft_dirty(swp_pte);
set_pte_at(mm, address, pvmw.pte, swp_pte);
/* Invalidate as we cleared the pte */
mmu_notifier_invalidate_range(mm, address,
address + PAGE_SIZE);
} else {
/*
* This is a locked file-backed page, thus it cannot
* be removed from the page cache and replaced by a new
* page before mmu_notifier_invalidate_range_end, so no
* concurrent thread might update its page table to
* point at new page while a device still is using this
* page.
*
* See Documentation/vm/mmu_notifier.rst
*/
dec_mm_counter(mm, mm_counter_file(page));
}
discard:
/*
* No need to call mmu_notifier_invalidate_range() it has be
* done above for all cases requiring it to happen under page
* table lock before mmu_notifier_invalidate_range_end()
*
* See Documentation/vm/mmu_notifier.rst
*/
page_remove_rmap(subpage, PageHuge(page)); // 这里会减少 _mapcount
put_page(page); // 这里会减少 _refcount
}
get_unmapped_area
shared anon 的内存实际上是关联了文件的
#0 shmem_zero_setup (vma=vma@entry=0xffff88812c40d558) at mm/shmem.c:4227
#1 0xffffffff812e6a49 in mmap_region (file=file@entry=0x0 <fixed_percpu_data>, addr=addr@entry=140537761943552, len=len@entry=4096, vm_flags=vm_flags@entry=251, pgoff=0, uf=uf@entry=0xffffc9000201bef0) at mm/mmap.c:2665
#2 0xffffffff812e6f2f in do_mmap (file=file@entry=0x0 <fixed_percpu_data>, addr=140537761943552, addr@entry=0, len=4096, len@entry=4, prot=<optimized out>, prot@entry=3, flags=flags@entry=33, pgoff=<optimized out>, pgoff@entry=0, populate=0xffffc9000201bee8, uf=0xffffc9000201bef0) at mm/mmap.c:1412
#3 0xffffffff812b9a55 in vm_mmap_pgoff (file=0x0 <fixed_percpu_data>, addr=0, len=4, prot=3, flag=33, pgoff=0) at mm/util.c:520
#4 0xffffffff81fa4bdb in do_syscall_x64 (nr=<optimized out>, regs=0xffffc9000201bf58) at arch/x86/entry/common.c:50
#5 do_syscall_64 (regs=0xffffc9000201bf58, nr=<optimized out>) at arch/x86/entry/common.c:80
#6 0xffffffff8200009b in entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
从内核的角度来看,也就是 vma_is_anonymous ,是判断 vm_ops,在 shmem_zero_setup 中,会为该 anon share 创建一个文件。
https://stackoverflow.com/questions/13274786/how-to-share-memory-between-processes-created-by-fork
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
static int *glob_var;
int main(void) {
glob_var = mmap(NULL, sizeof *glob_var, PROT_READ | PROT_WRITE,
MAP_SHARED | MAP_ANONYMOUS, -1, 0);
if (fork() == 0) {
*glob_var = 5;
exit(EXIT_SUCCESS);
} else {
wait(NULL);
printf("%d\n", *glob_var);
munmap(glob_var, sizeof *glob_var);
}
return 0;
}
shared anon 就是完全和 shmem 放到一起的,在 /proc/meminfo 的影响都一样。
show_val_kb(m, "Mapped: ",
global_node_page_state(NR_FILE_MAPPED));
映射会增加 shared memory 的大小的。
page_mapped 和 page_mapping
- page_mapped : 返回是否映射到地址空间中
- page_mapping : 返回关联的 file
struct address_space *page_mapping(struct page *page) bool page_mapped(struct page *page)
- page_mapcount =
_mapcount+ 1 表示该 page 出现在 page table 的次数
可以动态修改 mmap 的属性吗? 将 shared 修改为 private
看看,有趣的
既然操作系统层已经提供了 page cache 的功能,为什么还要在应用层加缓存? - 刘逸群的回答 - 知乎 https://www.zhihu.com/question/29203599/answer/2984747895 https://news.ycombinator.com/item?id=29936104
再次回答这个问题,为什么不去使用 mmap 来做存储?
neovim 使用的 mmap 吗?
获取说,mmap 的性能是什么样的,mmap 只能用于动态库的共享吗?
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。