Page Reclaim
问题
- 对于 dirty memory 和 clean mmeory 的 scan 应该是不同的吧
- lruvec 一共有多少个,处理的时候的规则是怎样的
- 如果整个分配都是在 zone 上进行,那么为什么 reclaim 机制又是在 node 上完成的
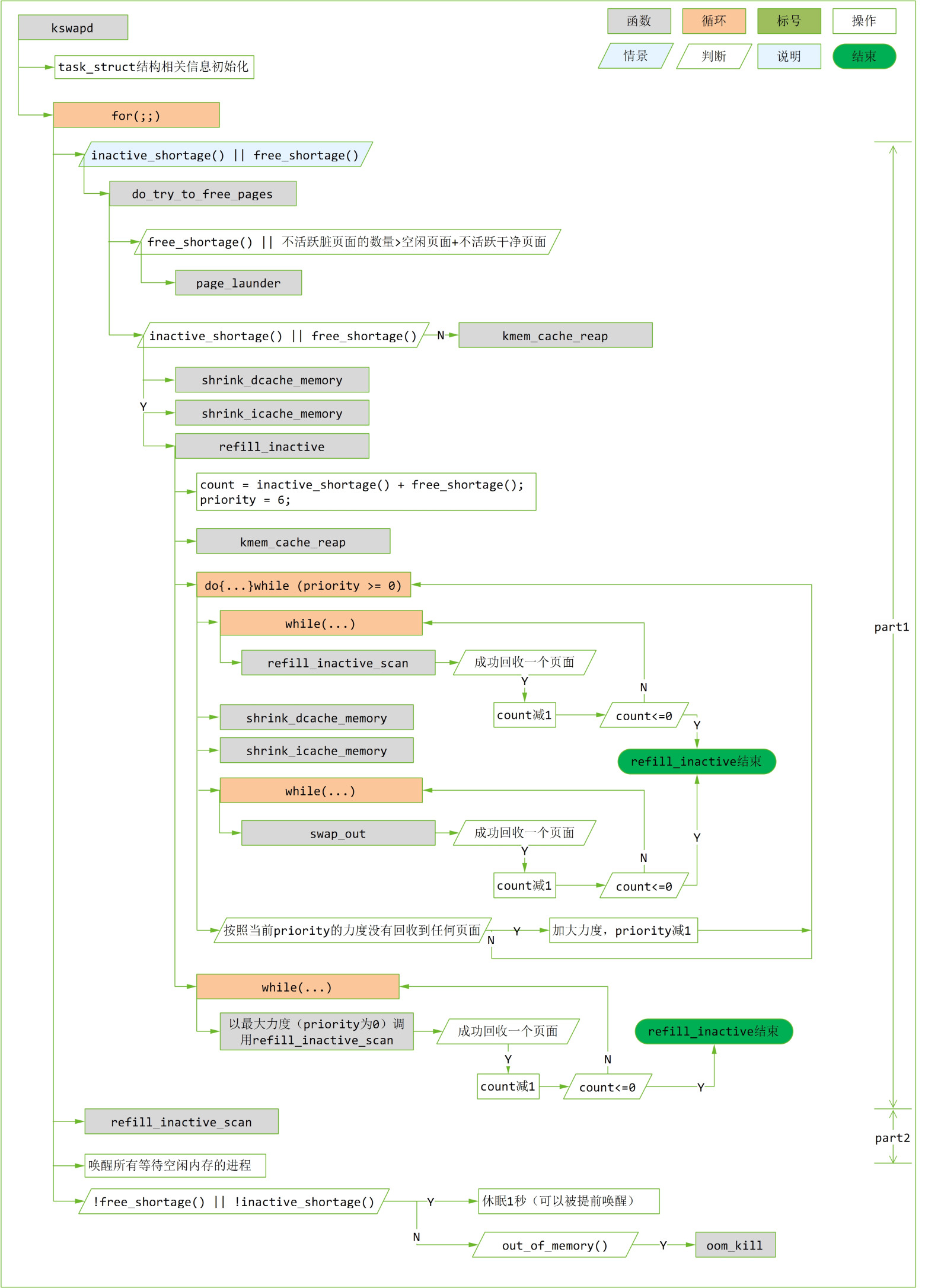
kswapd
- 描述主动和被动触发的流程
- 每一个 numa 一个 kswapd,确认下
转换的方法 : mark_page_accessed 和 folio_check_references
两个 bit : PG_active 和 PG_referenced
- mark_page_accessed 是 folio_mark_accessed 的封装
- 为什么 kvm 要调用这个,
- folio_check_references
- 在扫描 inactive list 的时候调用,返回决定该 page 的四个状态
总体来说,mark_page_accessed / folio_mark_accessed 是内核的执行过程中, 将页进行标记,说明其一定是活跃的,但是一个页被读写之后,分配之后,可能被用户程序长时间的访问, 这个就要靠 folio_check_references。
这个逻辑好奇怪啊,为什么在 exit 的时候还需要来 mark_page_accessed 一下
一般来说,是这个调用路径
#0 touch_buffer (bh=<optimized out>) at fs/buffer.c:62
#1 __find_get_block (bdev=0xffff888161ba9200, block=11534947, size=<optimized out>) at fs/buffer.c:1311
#2 0xffffffff813adb3f in __getblk_gfp (bdev=0xffff888161ba9200, block=block@entry=11534947, size=4096, gfp=gfp@entry=8) at fs/buffer.c:1329
#3 0xffffffff8142408c in sb_getblk (block=11534947, sb=0xffff8881215e4800) at include/linux/buffer_head.h:356
#4 __ext4_get_inode_loc (sb=0xffff8881215e4800, ino=2892864, inode=inode@entry=0xffff888166f24610, iloc=iloc@entry=0xffffc9000175bcb0, ret_block=ret_block@entry=0xffffc9000175bc58) at fs/ext4/inode.c:4479
#5 0xffffffff81426389 in ext4_get_inode_loc (inode=inode@entry=0xffff888166f24610, iloc=iloc@entry=0xffffc9000175bcb0) at fs/ext4/inode.c:4607
#6 0xffffffff81427d96 in ext4_reserve_inode_write (handle=handle@entry=0xffff888166c415e8, inode=inode@entry=0xffff888166f24610, iloc=iloc@entry=0xffffc9000175bcb0) at fs/ext4/inode.c:5804
#7 0xffffffff81428012 in __ext4_mark_inode_dirty (handle=handle@entry=0xffff888166c415e8, inode=inode@entry=0xffff888166f24610, func=func@entry=0xffffffff8244ceb0 <__func__.36> "ext4_ext_tree_init", line=line@entry=879) at fs/ext4/inode.c:5973
#8 0xffffffff8140afd7 in ext4_ext_tree_init (handle=handle@entry=0xffff888166c415e8, inode=inode@entry=0xffff888166f24610) at fs/ext4/extents.c:879
#9 0xffffffff8141b797 in __ext4_new_inode (mnt_userns=mnt_userns@entry=0xffffffff82a627c0 <init_user_ns>, handle=0xffff888166c415e8, handle@entry=0x0 <fixed_percpu_data>, dir=dir@entry=0xffff8881240ee1a0, mode=mode@entry=41471, qstr=qstr@entry=0xffff888166debb60, goal=<optimized out>, goal@entry=0, owner=<optimized out>, i_flags=<optimized out>, handle_type=<optimized out>, line_no=<optimized out>, nblocks=<optimized out>) at fs/ext4/ialloc.c:1333
#10 0xffffffff81443977 in ext4_symlink (mnt_userns=0xffffffff82a627c0 <init_user_ns>, dir=0xffff8881240ee1a0, dentry=<optimized out>, symname=<optimized out>) at fs/ext4/namei.c:3361
#11 0xffffffff813745ac in vfs_symlink (oldname=0xffff888162cd8020 "/pid-1092/host-localhost.localdomain", dentry=0xffff888166debb40, dir=0xffff8881240ee1a0, mnt_userns=0xffffffff82a627c0 <init_user_ns>) at fs/namei.c:4400
#12 vfs_symlink (mnt_userns=0xffffffff82a627c0 <init_user_ns>, dir=0xffff8881240ee1a0, dentry=0xffff888166debb40, oldname=0xffff888162cd8020 "/pid-1092/host-localhost.localdomain") at fs/namei.c:4385
#13 0xffffffff8137a0f5 in do_symlinkat (from=0xffff888162cd8000, newdfd=newdfd@entry=-100, to=to@entry=0xffff888162cde000) at fs/namei.c:4429
#14 0xffffffff8137a293 in __do_sys_symlink (newname=<optimized out>, oldname=0x5626a6d08830 "/pid-1092/host-localhost.localdomain") at fs/namei.c:4451
#15 __se_sys_symlink (newname=<optimized out>, oldname=<optimized out>) at fs/namei.c:4449
#16 __x64_sys_symlink (regs=<optimized out>) at fs/namei.c:4449
#17 0xffffffff81fa3bdb in do_syscall_x64 (nr=<optimized out>, regs=0xffffc9000175bf58) at arch/x86/entry/common.c:50
#18 do_syscall_64 (regs=0xffffc9000175bf58, nr=<optimized out>) at arch/x86/entry/common.c:80
#19 0xffffffff8200009b in entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
page reclaim
keynote
- get_scan_count : 没有 swap 分区的时候,不会处理 anonymous page lru
TODO
- 奔跑吧 P310 对于 shrink 函数逐行分析,并没有阅读
dirty file page 是如何被释放的
- 出现内存压力,会加快的 dirty page 的写回吗?
shrink_inactive_list 中存在如下代码:
/*
* If dirty folios are scanned that are not queued for IO, it
* implies that flushers are not doing their job. This can
* happen when memory pressure pushes dirty folios to the end of
* the LRU before the dirty limits are breached and the dirty
* data has expired. It can also happen when the proportion of
* dirty folios grows not through writes but through memory
* pressure reclaiming all the clean cache. And in some cases,
* the flushers simply cannot keep up with the allocation
* rate. Nudge the flusher threads in case they are asleep.
*/
if (stat.nr_unqueued_dirty == nr_taken) {
wakeup_flusher_threads(WB_REASON_VMSCAN);
/*
* For cgroupv1 dirty throttling is achieved by waking up
* the kernel flusher here and later waiting on folios
* which are in writeback to finish (see shrink_folio_list()).
*
* Flusher may not be able to issue writeback quickly
* enough for cgroupv1 writeback throttling to work
* on a large system.
*/
if (!writeback_throttling_sane(sc))
reclaim_throttle(pgdat, VMSCAN_THROTTLE_WRITEBACK);
}
dirty anon page
shrink_folio_list 中:
- 如果是匿名页面,调用 add_to_swap 加入到 swapcache 中:
- 写回,但是无需等待存储设备的返回,page 放到 inactive lru 的头中。
- 如果 clean 了,在下次扫描的过程中,在
__remove_mapping中释放 page 。
direct shrink
-
So, where’s indirect shrink, polish documentations here.
-
LoyenWang section 3.3
kswapd
-
[^29] present a beautiful graph
-
relation between
kswapdandkcompactd: if kswapd free some pages, then we can wake it up and compact pages
shrink_node
get_scan_count
enum scan_balance {
SCAN_EQUAL, // 计算出的扫描值按原样使用
SCAN_FRACT, // 将分数应用于计算的扫描值
SCAN_ANON, // 对于文件页LRU,将扫描次数更改为0
SCAN_FILE, // 对于匿名页LRU,将扫描次数更改为0
};
watch out : rename shrink_node_memcg to shrink_lruvec
Per memcg lru locking
-
shrink_zones / balance_pgdat
- mem_cgroup_soft_limit_reclaim
reclaim flag 如何使用的
在 lru_deactivate_file_fn 中,如果当时 page 有 dirty 或者 writeback 的,那么 设置上 reclaim .
看注释,其含义应该是当该 page 需要 immediate reclaim
/*
* The number of dirty pages determines if a node is marked
* reclaim_congested. kswapd will stall and start writing
* folios if the tail of the LRU is all dirty unqueued folios.
*/
- 通过 PG_reclaim 是可以检测到 tail of the LRU is all dirty unqueued folios 吗?
在这个 commit 将 if 修改为 while ,可以尝试理解下:
- c2407cf7d22d0c0d94cf20342b3b8f06f1d904e7
如何理解 buffer_heads_over_limit
如果 buffer cache 超过 10%
if (unlikely(buffer_heads_over_limit)) {
if (folio_test_private(folio) && folio_trylock(folio)) {
if (folio_test_private(folio))
filemap_release_folio(folio, 0);
folio_unlock(folio);
}
}
如何理解 priority
/*
* The "priority" of VM scanning is how much of the queues we will scan in one
* go. A value of 12 for DEF_PRIORITY implies that we will scan 1/4096th of the
* queues ("queue_length >> 12") during an aging round.
*/
#define DEF_PRIORITY 12
一次扫描 queue_length » 12 ,那么什么叫做 an aging round ?
先调查其他的问题了,以后再说吧!
swappiness
- https://unix.stackexchange.com/questions/697448/what-is-the-replacement-of-memory-swappiness-file-in-cgroups-v2
cgroupv2 中,只有全局的 swappiness
-
/proc/sys/vm/swappiness 是全局的,如何影响到具体的 cgroup 的
-
shrink_lruvec 使用过
static inline int mem_cgroup_swappiness(struct mem_cgroup *memcg)
{
/* Cgroup2 doesn't have per-cgroup swappiness */
if (cgroup_subsys_on_dfl(memory_cgrp_subsys))
return vm_swappiness;
/* root ? */
if (mem_cgroup_disabled() || mem_cgroup_is_root(memcg))
return vm_swappiness;
return memcg->swappiness;
}
- mem_cgroup_swappiness 起作用的位置在 get_scan_count,而 shrink_lruvec 是 get_scan_count 的位置。
- lru_note_cost
#0 lru_note_cost (lruvec=lruvec@entry=0xffff8883422ea800, file=file@entry=true, nr_io=0, nr_rotated=0) at mm/swap.c:301
#1 0xffffffff812f99f0 in shrink_inactive_list (lru=LRU_INACTIVE_FILE, sc=0xffffc90003d6bdd8, lruvec=0xffff8883422ea800, nr_to_scan=<optimized out>) at mm/vmscan.c:2539
#2 shrink_list (sc=0xffffc90003d6bdd8, lruvec=0xffff8883422ea800, nr_to_scan=<optimized out>, lru=LRU_INACTIVE_FILE) at mm/vmscan.c:2767
#3 shrink_lruvec (lruvec=lruvec@entry=0xffff8883422ea800, sc=sc@entry=0xffffc90003d6bdd8) at mm/vmscan.c:5951
#4 0xffffffff812fa20e in shrink_node_memcgs (sc=0xffffc90003d6bdd8, pgdat=0xffff8883bfffc000) at mm/vmscan.c:6138
#5 shrink_node (pgdat=pgdat@entry=0xffff8883bfffc000, sc=sc@entry=0xffffc90003d6bdd8) at mm/vmscan.c:6169
#6 0xffffffff812fa957 in kswapd_shrink_node (sc=0xffffc90003d6bdd8, pgdat=0xffff8883bfffc000) at mm/vmscan.c:6960
#7 balance_pgdat (pgdat=pgdat@entry=0xffff8883bfffc000, order=order@entry=0, highest_zoneidx=highest_zoneidx@entry=2) at mm/vmscan.c:7150
#8 0xffffffff812faf2f in kswapd (p=0xffff8883bfffc000) at mm/vmscan.c:7410
#9 0xffffffff811546e4 in kthread (_create=0xffff888101ca1680) at kernel/kthread.c:376
#10 0xffffffff81002659 in ret_from_fork () at arch/x86/entry/entry_64.S:308
#11 0x0000000000000000 in ?? ()
- 才意识到,shrink 对于 file 和 anon 分开的,所以每次从文件中取出来的数量是不同的
- 当 swappiness 是 60 的时候,大致可以理解从 anon 中取 60 个,从 file 中去 140 个 (当然没具体分析了)
- 直接清理 clean 的 page cache 不是最简单的吗?
- 或者说,swappiness 在尝试设置到底换出 page cache 还是
分析一下
- 如果首先 mmap 一个 anon 区域,然后 read 文件到其中
🤒 cat memory.stat | grep active
inactive_anon 8192
active_anon 8388702208
inactive_file 8388608000
active_file 0
- anon 默认的时候都是会设置为 active 的
- file 默认为 inactive 的
- 为什么正好两个 anon 的页是 inactive
@[
folio_add_lru+5
do_anonymous_page+766
__handle_mm_fault+2093
handle_mm_fault+341
do_user_addr_fault+351
exc_page_fault+109
asm_exc_page_fault+38
]: 7899
@[
folio_add_lru+5
filemap_add_folio+90
page_cache_ra_order+413
filemap_get_pages+1246
filemap_read+223
xfs_file_buffered_read+79
xfs_file_read_iter+110
vfs_read+499
ksys_read+111
do_syscall_64+59
entry_SYSCALL_64_after_hwframe+114
]: 420691
应该存在 2048000 个 page 的。 folio_mark_accessed
这个应该是设置 page
@[
folio_mark_accessed+5
filemap_read+584
xfs_file_buffered_read+79
xfs_file_read_iter+110
vfs_read+499
ksys_read+111
do_syscall_64+59
entry_SYSCALL_64_after_hwframe+114
]: 392674
才发现 folio_check_references -> folio_referenced 必须 rmap 一下
就算是 anon private 这种映射唯一的 page , 但是 walk va 来检查,没有这个问题。
cgroup 中的扫描也可以多线程的吗?
- 应该是的, 在 cgroup 中的多个 thread 同时分配内存,他们遇到问题,那么必然需要同时来想要获取到这个锁的
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。