- https://github.com/hamadmarri/cacule-cpu-scheduler : 新的一个 scheduler patch
- https://mp.weixin.qq.com/s/eFvu-tZNpIXaadYHDdkFSQ
主要参考资料
- loyenwang
- wowo
- 奔跑
总结
task_tick_fair

- check_preempt_tick : 检查当前进程的 vruntime ,如果是,那么可以继续运行
#0 update_curr (cfs_rq=cfs_rq@entry=0xffff88807dc2b340) at kernel/sched/fair.c:887
#1 0xffffffff81142b50 in dequeue_entity (flags=9, se=0xffff8881001b8f80, cfs_rq=0xffff88807dc2b340) at kernel/sched/fair.c:4517
#2 dequeue_task_fair (rq=0xffff88807dc2b2c0, p=0xffff8881001b8f00, flags=9) at kernel/sched/fair.c:5835
#3 0xffffffff81f40186 in dequeue_task (flags=9, p=0xffff8881001b8f00, rq=0xffff88807dc2b2c0) at kernel/sched/core.c:2086
#4 deactivate_task (flags=9, p=0xffff8881001b8f00, rq=0xffff88807dc2b2c0) at kernel/sched/core.c:2100
#5 __schedule (sched_mode=sched_mode@entry=0) at kernel/sched/core.c:6448
#6 0xffffffff81f40595 in schedule () at kernel/sched/core.c:6570
#7 0xffffffff8112aee1 in kthreadd (unused=<optimized out>) at kernel/kthread.c:733
#8 0xffffffff81001a72 in ret_from_fork () at arch/x86/entry/entry_64.S:306
#9 0x0000000000000000 in ?? ()
enqueue_task_fair
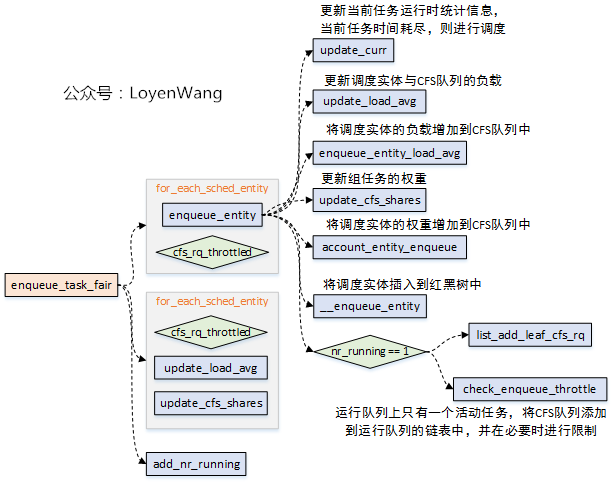
当一个 thread 就绪之后就会通过调用 enqueue_task_fair 放到 cfs 的 rb tree 中:
#0 dequeue_task_fair (rq=0xffff88807dc2b2c0, p=0xffff8881001b8f00, flags=9) at kernel/sched/fair.c:5824
#1 0xffffffff81f40186 in dequeue_task (flags=9, p=0xffff8881001b8f00, rq=0xffff88807dc2b2c0) at kernel/sched/core.c:2086
#2 deactivate_task (flags=9, p=0xffff8881001b8f00, rq=0xffff88807dc2b2c0) at kernel/sched/core.c:2100
#3 __schedule (sched_mode=sched_mode@entry=0) at kernel/sched/core.c:6448
#4 0xffffffff81f40595 in schedule () at kernel/sched/core.c:6570
#5 0xffffffff8112aee1 in kthreadd (unused=<optimized out>) at kernel/kthread.c:733
#6 0xffffffff81001a72 in ret_from_fork () at arch/x86/entry/entry_64.S:306
#7 0x0000000000000000 in ?? ()
dequeue_task_fair
总体来说, dequeue_task_fair 在于和 bandwidth group 相关的更新 enqueue_task_fair 和其效果非常的相似




pick_next_task

__schedule- pick_next_task
- pick_task : 使用 for_each_class 将所有的 sched_class::pick_task 遍历一次
__pick_next_task- pick_next_task_fair
- pick_task : 使用 for_each_class 将所有的 sched_class::pick_task 遍历一次
- pick_next_task
select_task_rq_fair
- 这个是做啥的
#0 select_task_rq_fair (p=0xffff88814a11ae80, prev_cpu=0, wake_flags=8) at kernel/sched/fair.c:7015 #1 0xffffffff8113cff4 in select_task_rq (wake_flags=8, cpu=0, p=0xffff88814a11ae80) at kernel/sched/core.c:3489 #2 try_to_wake_up (p=0xffff88814a11ae80, state=state@entry=3, wake_flags=wake_flags@entry=0) at kernel/sched/core.c:4183 #3 0xffffffff8113d3cc in wake_up_process (p=<optimized out>) at kernel/sched/core.c:4314 #4 0xffffffff8119b859 in hrtimer_wakeup (timer=<optimized out>) at kernel/time/hrtimer.c:1939 #5 0xffffffff8119bde2 in __run_hrtimer (flags=2, now=0xffffc90000003f48, timer=0xffffc900005bb910, base=0xffff888333c1e0c0, cpu_base=0xffff888333c1e080) at kernel/time/hrtimer.c:1685 #6 __hrtimer_run_queues (cpu_base=cpu_base@entry=0xffff888333c1e080, now=48877213737236, flags=flags@entry=2, active_mask=active_mask@entry=15) at kernel/time/hrtimer.c:1749 #7 0xffffffff8119ca71 in hrtimer_interrupt (dev=<optimized out>) at kernel/time/hrtimer.c:1811 #8 0xffffffff810e25d7 in local_apic_timer_interrupt () at arch/x86/kernel/apic/apic.c:1095 #9 __sysvec_apic_timer_interrupt (regs=<optimized out>) at arch/x86/kernel/apic/apic.c:1112 #10 0xffffffff81f4137d in sysvec_apic_timer_interrupt (regs=0xffffc9000086bd18) at arch/x86/kernel/apic/apic.c:1106
vruntime 的计算
- update_curr 中
- curr->vruntime += calc_delta_fair(delta_exec, curr);
- update_min_vruntime : Each time a new task forks or a task wakes up, its vruntime is assigned to a value that is the maximum of its last updated value and cfs_rq.min_vruntime.
The lowest vruntime found in the queue is stored in
cfs_rq.min_vruntime. When a new task is picked to run, the leftmost node of the red-black tree is chosen since that task has had the least running time on the CPU. Each time a new task forks or a task wakes up, its vruntime is assigned to a value that is the maximum of its last updated value and cfs_rq.min_vruntime. If not for this, its vruntime would be very small as an effect of not having run for a long time (or at all) and would take an unacceptably long time to catch up to the vruntime of its sibling tasks and hence starve them of CPU time.
使用的 rb_tree 的比较函数为 __entity_less,使用 sched_entity::vruntime 实现的
整理一下 kernel 的 doc
A group’s unassigned quota is globally tracked, being refreshed back to cfs_quota units at each period boundary. As threads consume this bandwidth it is transferred to cpu-local “silos” on a demand basis. The amount transferred within each of these updates is tunable and described as the “slice”.
For efficiency run-time is transferred between the global pool and CPU local “silos” in a batch fashion.
sched_entity 是否对应的
看上去,sched_entity 和 rq 对应:
- se 特指给 cfs_rq 使用 ?
- 如果真的是仅仅作为 rb tree 中间的一个 node 显然没有必要高处三个来!
- so many update load avg:
- update_tg_load_avg
- update_load_avg
- rebalance_domains : 处理 idle , balance 的时机
- load_balance
CFS 线程调度机制分析
#0 wakeup_gran (se=0xffff888104446680) at kernel/sched/fair.c:7731
#1 wakeup_preempt_entity (curr=0xffff888104162280, curr=0xffff888104162280, se=0xffff888104446680) at kernel/sched/fair.c:7756
#2 check_preempt_wakeup (rq=0xffff888333bee200, p=<optimized out>, wake_flags=<optimized out>) at kernel/sched/fair.c:7861
#3 0xffffffff81186831 in check_preempt_curr (rq=rq@entry=0xffff888333bee200, p=p@entry=0xffff888104446600, flags=flags@entry=0) at kernel/sched/core.c:2182
#4 0xffffffff811868bd in ttwu_do_activate (rq=rq@entry=0xffff888333bee200, p=p@entry=0xffff888104446600, wake_flags=wake_flags@entry=0, rf=<optimized
out>) at kernel/sched/core.c:3713
#5 0xffffffff811877eb in ttwu_queue (wake_flags=0, cpu=<optimized out>, p=0xffff888104446600) at kernel/sched/core.c:3956
#6 try_to_wake_up (p=0xffff888104446600, state=state@entry=3, wake_flags=wake_flags@entry=0) at kernel/sched/core.c:4278
#7 0xffffffff81187b95 in wake_up_process (p=<optimized out>) at kernel/sched/core.c:4412
#8 0xffffffff81164780 in wake_up_worker (pool=<optimized out>) at kernel/workqueue.c:859
#9 insert_work (extra_flags=0, head=<optimized out>, work=0xffff888333beaea0, pwq=0xffff888333bf4600) at kernel/workqueue.c:1369
#10 __queue_work (cpu=23, wq=<optimized out>, work=0xffff888333beaea0) at kernel/workqueue.c:1524
#11 0xffffffff81203657 in call_timer_fn (timer=timer@entry=0xffff888333beaec0, fn=fn@entry=0xffffffff811650e0 <delayed_work_timer_fn>, baseclk=baseclk
@entry=4294686976) at kernel/time/timer.c:1700
#12 0xffffffff812038ee in expire_timers (head=0xffffc90002073e50, base=0xffff888333bde300) at kernel/time/timer.c:1746
#13 __run_timers (base=0xffff888333bde300) at kernel/time/timer.c:2022
#14 0xffffffff822983c7 in __do_softirq () at kernel/softirq.c:571
#15 0xffffffff81149646 in invoke_softirq () at kernel/softirq.c:445
#16 __irq_exit_rcu () at kernel/softirq.c:650
#17 0xffffffff81149e4e in irq_exit_rcu () at kernel/softirq.c:662
#18 0xffffffff822821a0 in sysvec_apic_timer_interrupt (regs=0xffffc90002073f58) at arch/x86/kernel/apic/apic.c:1107
#19 0xffffffff8240148a in asm_sysvec_apic_timer_interrupt () at ./arch/x86/include/asm/idtentry.h:645
其中还有几个小实验可以分析下。
runtime vruntime
cfs
- 运行时间 runtime 可以转换成虚拟运行时间 vruntime;
- what if vruntime overflow ?
struct sched_entity {
/* For load-balancing: */
struct load_weight load; //调度实体的负载权重值
struct rb_node run_node; //用于连接到CFS运行队列的红黑树中的节点
struct list_head group_node; //用于连接到CFS运行队列的cfs_tasks链表中的节点
unsigned int on_rq; //用于表示是否在运行队列中
u64 exec_start; //当前调度实体的开始执行时间
u64 sum_exec_runtime; //调度实体执行的总时间
u64 vruntime; //虚拟运行时间,这个时间用于在CFS运行队列中排队
u64 prev_sum_exec_runtime;//上一个调度实体运行的总时间
u64 nr_migrations; //负载均衡
致命问题
- what’s relation with
load,priority,weightandshare?
重新搞懂 scheudler 的计划
- 先让 AI 过一遍文档吧
- 先搞懂如何使用,不要看代码
- 基本 syscall
- cgroup
- sched_ext
- cpu.cfs_quota_us
其实还是那个问题,似乎 scheudler 的各种特性都没用熟悉, 就不要一天到晚看 scheduler 的实现了。
rq_offline_fair 和 rq_online_fair 的作用是什么
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。