load avg
#0 update_load_avg (cfs_rq=0xffff888145898200, se=0xffff88814a10af00, flags=1) at kernel/sched/fair.c:4009
#1 0xffffffff81145747 in entity_tick (queued=0, curr=0xffff88814a10af00, cfs_rq=0xffff888145898200) at kernel/sched/fair.c:4740
#2 task_tick_fair (rq=0xffff888333d2b2c0, curr=0xffff88814a10ae80, queued=0) at kernel/sched/fair.c:11416
#3 0xffffffff8113f392 in scheduler_tick () at kernel/sched/core.c:5453
#4 0xffffffff8119b2b1 in update_process_times (user_tick=0) at kernel/time/timer.c:1844
#5 0xffffffff811ad85f in tick_sched_handle (ts=ts@entry=0xffff888333d1e5c0, regs=regs@entry=0xffffc900000c8ee8) at kernel/time/tick-sched.c:243
#6 0xffffffff811ada3c in tick_sched_timer (timer=0xffff888333d1e5c0) at kernel/time/tick-sched.c:1480
#7 0xffffffff8119bde2 in __run_hrtimer (flags=130, now=0xffffc900000c8e20, timer=0xffff888333d1e5c0, base=0xffff888333d1e0c0, cpu_base=0xffff888333d1e080) at kernel/time/hrtimer.c:1685
#8 __hrtimer_run_queues (cpu_base=cpu_base@entry=0xffff888333d1e080, now=48647511875190, flags=flags@entry=130, active_mask=active_mask@entry=15) at kernel/time/hrtimer.c:1749
#9 0xffffffff8119ca71 in hrtimer_interrupt (dev=<optimized out>) at kernel/time/hrtimer.c:1811
- update_load_avg
- propagate_entity_load_avg
- update_tg_cfs_util
- update_tg_cfs_runnable
- update_tg_cfs_load
- propagate_entity_load_avg
update_load_avg
这个函数感觉仅仅像是一个搭桥的函数
/*
* The load_avg/util_avg accumulates an infinite geometric series
* (see __update_load_avg() in kernel/sched/fair.c).
*
* [load_avg definition]
*
* load_avg = runnable% * scale_load_down(load)
*
* where runnable% is the time ratio that a sched_entity is runnable.
* For cfs_rq, it is the aggregated load_avg of all runnable and
* blocked sched_entities.
*
* load_avg may also take frequency scaling into account:
*
* load_avg = runnable% * scale_load_down(load) * freq%
*
* where freq% is the CPU frequency normalized to the highest frequency.
*
* [util_avg definition]
*
* util_avg = running% * SCHED_CAPACITY_SCALE
*
* where running% is the time ratio that a sched_entity is running on
* a CPU. For cfs_rq, it is the aggregated util_avg of all runnable
* and blocked sched_entities.
*
* util_avg may also factor frequency scaling and CPU capacity scaling:
*
* util_avg = running% * SCHED_CAPACITY_SCALE * freq% * capacity%
*
* where freq% is the same as above, and capacity% is the CPU capacity
* normalized to the greatest capacity (due to uarch differences, etc).
*
* N.B., the above ratios (runnable%, running%, freq%, and capacity%)
* themselves are in the range of [0, 1]. To do fixed point arithmetics,
* we therefore scale them to as large a range as necessary. This is for
* example reflected by util_avg's SCHED_CAPACITY_SCALE.
*
* [Overflow issue]
*
* The 64-bit load_sum can have 4353082796 (=2^64/47742/88761) entities
* with the highest load (=88761), always runnable on a single cfs_rq,
* and should not overflow as the number already hits PID_MAX_LIMIT.
*
* For all other cases (including 32-bit kernels), struct load_weight's
* weight will overflow first before we do, because:
*
* Max(load_avg) <= Max(load.weight)
*
* Then it is the load_weight's responsibility to consider overflow
* issues.
*/
struct sched_avg {
load
static unsigned long cpu_load(struct rq *rq)
{
return cfs_rq_load_avg(&rq->cfs);
}
/*
* The load/runnable/util_avg accumulates an infinite geometric series
* (see __update_load_avg_cfs_rq() in kernel/sched/pelt.c).
*
* [load_avg definition]
*
* load_avg = runnable% * scale_load_down(load)
*
* [runnable_avg definition]
*
* runnable_avg = runnable% * SCHED_CAPACITY_SCALE
*
* [util_avg definition]
*
* util_avg = running% * SCHED_CAPACITY_SCALE
*
* where runnable% is the time ratio that a sched_entity is runnable and
* running% the time ratio that a sched_entity is running.
*
* For cfs_rq, they are the aggregated values of all runnable and blocked
* sched_entities.
*
* The load/runnable/util_avg doesn't directly factor frequency scaling and CPU
* capacity scaling. The scaling is done through the rq_clock_pelt that is used
* for computing those signals (see update_rq_clock_pelt())
*
* N.B., the above ratios (runnable% and running%) themselves are in the
* range of [0, 1]. To do fixed point arithmetics, we therefore scale them
* to as large a range as necessary. This is for example reflected by
* util_avg's SCHED_CAPACITY_SCALE.
*
* [Overflow issue]
*
* The 64-bit load_sum can have 4353082796 (=2^64/47742/88761) entities
* with the highest load (=88761), always runnable on a single cfs_rq,
* and should not overflow as the number already hits PID_MAX_LIMIT.
*
* For all other cases (including 32-bit kernels), struct load_weight's
* weight will overflow first before we do, because:
*
* Max(load_avg) <= Max(load.weight)
*
* Then it is the load_weight's responsibility to consider overflow
* issues.
*/
struct sched_avg {
u64 last_update_time;
u64 load_sum;
u64 runnable_sum;
u32 util_sum;
u32 period_contrib;
unsigned long load_avg;
unsigned long runnable_avg;
unsigned long util_avg;
struct util_est util_est;
} ____cacheline_aligned;
首先,一共三个数值,load, runnable, util, 这三个都是无穷级数
- 表示可运行状态,在就绪队列可运行状态,和正在执行
- 所以 可运行状态 和 在就绪队列 真的区分了吗 ?
- 确实如此表述的
其次,两个对象,sched_entities 和 rq
- load_sum 对于 entity 只是衰减时间,而对于 rq 是 时间 乘以 权重
- 分析
__update_load_avg_se和__update_load_avg_cfs_rq,就 load,前者是 1 ,而后者是scale_load_down(cfs_rq->load.weight)
- 分析
- 分析
___update_load_avg, 其实 avg 的作用对于 cfs_rq 就是除以get_pelt_divider- 但是对于 se 来说,load 参数为其 weight
static __always_inline void
___update_load_avg(struct sched_avg *sa, unsigned long load)
{
u32 divider = get_pelt_divider(sa);
/*
* Step 2: update *_avg.
*/
sa->load_avg = div_u64(load * sa->load_sum, divider);
sa->runnable_avg = div_u64(sa->runnable_sum, divider);
WRITE_ONCE(sa->util_avg, sa->util_sum / divider);
}
/*
* sched_entity:
*
* task:
* se_weight() = se->load.weight
* se_runnable() = !!on_rq
*
* group: [ see update_cfs_group() ]
* se_weight() = tg->weight * grq->load_avg / tg->load_avg
* se_runnable() = grq->h_nr_running
*
* runnable_sum = se_runnable() * runnable = grq->runnable_sum
* runnable_avg = runnable_sum
*
* load_sum := runnable
* load_avg = se_weight(se) * load_sum
*
* cfq_rq:
*
* runnable_sum = \Sum se->avg.runnable_sum
* runnable_avg = \Sum se->avg.runnable_avg
*
* load_sum = \Sum se_weight(se) * se->avg.load_sum
* load_avg = \Sum se->avg.load_avg
*/
int __update_load_avg_se(u64 now, struct cfs_rq *cfs_rq, struct sched_entity *se)
{
if (___update_load_sum(now, &se->avg, !!se->on_rq, se_runnable(se),
cfs_rq->curr == se)) {
___update_load_avg(&se->avg, se_weight(se));
cfs_se_util_change(&se->avg);
trace_pelt_se_tp(se);
return 1;
}
return 0;
}
int __update_load_avg_cfs_rq(u64 now, struct cfs_rq *cfs_rq)
{
if (___update_load_sum(now, &cfs_rq->avg,
scale_load_down(cfs_rq->load.weight),
cfs_rq->h_nr_running,
cfs_rq->curr != NULL)) {
___update_load_avg(&cfs_rq->avg, 1);
trace_pelt_cfs_tp(cfs_rq);
return 1;
}
return 0;
}
关于 load_avg 和 load_sum 在 rq 和 se 上的区别:
static inline void
enqueue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
cfs_rq->avg.load_avg += se->avg.load_avg;
cfs_rq->avg.load_sum += se_weight(se) * se->avg.load_sum;
}
static inline void
dequeue_load_avg(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
sub_positive(&cfs_rq->avg.load_avg, se->avg.load_avg);
sub_positive(&cfs_rq->avg.load_sum, se_weight(se) * se->avg.load_sum);
}
- 如果 load_avg 和 load_sum 靠这个来维持,那么为什么还存在
__update_load_avg_cfs_rq- 因为这两个函数是 task 加入到 cfs_rq 中的时候调用
- 上面两个函数还印证的想法 : se 的 sum 都是没有加入权重的,而 load_avg 是增加了权重的

- why has split time into period(1024ms)
- kernel can’t handle float
- why decay, how to decay ?
- maybe the reason is same with /proc/loadavg
- how to count the time is blocked , or runable ?
- 状态更新的时候,这些统计函数都会被使用
global load
- 忽然发现 /proc/loadavg 的计算不是利用上面的体系的
exported by /proc/loadavg
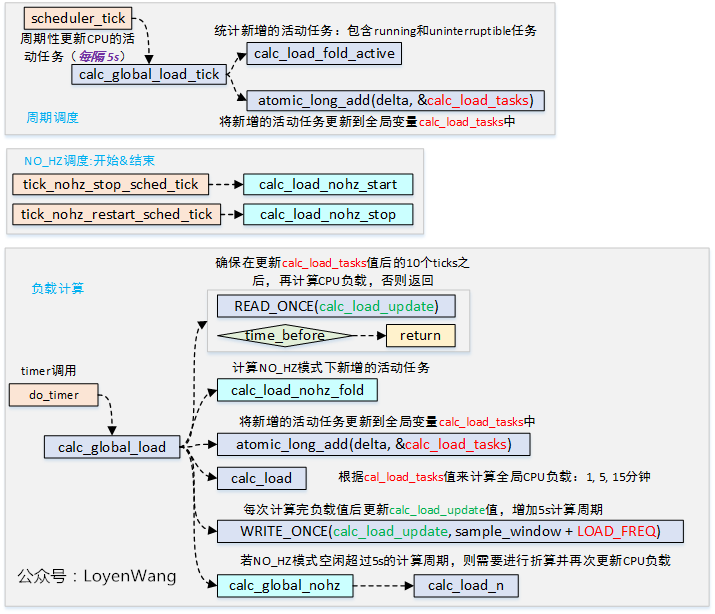
- scheduler_tick :
curr->sched_class->task_tick(rq, curr, 0);- calc_global_load_tick : update
calc_load_tasks - perf_event_task_tick
- do_timer : do the calculation
curr->sched_class->task_tick: what are we doing in it ?- what’s relation
do_timerandscheduler_tick?
loadavg decay at rate 1/e at 1min, 5min, 15min.
task_group
- struct task_group::load_avg
- struct cfs_rq::tg_load_avg_contrib; ```c /**
- update_tg_load_avg - update the tg’s load avg
- @cfs_rq: the cfs_rq whose avg changed
- @force: update regardless of how small the difference *
- This function ‘ensures’: tg->load_avg := \Sum tg->cfs_rq[]->avg.load.
- However, because tg->load_avg is a global value there are performance
- considerations. *
- In order to avoid having to look at the other cfs_rq’s, we use a
- differential update where we store the last value we propagated. This in
- turn allows skipping updates if the differential is ‘small’. *
- Updating tg’s load_avg is necessary before update_cfs_share(). */ static inline void update_tg_load_avg(struct cfs_rq *cfs_rq, int force)
/* Task group related information / struct task_group { / * load_avg can be heavily contended at clock tick time, so put * it in its own cacheline separated from the fields above which * will also be accessed at each tick. */ atomic_long_t load_avg ____cacheline_aligned;
As two comments suggests, `tg->load_avg := \Sum tg->cfs_rq[]->avg.load_avg.`, tg_load_avg_contrib is used for lock efficiency.
- cfs_rq 上挂在的 node 可能是 se, 可能是 tg
- task_group 会为每个 CPU 再维护一个 cfs_rq,这个 cfs_rq 用于组织挂在这个任务组上的任务以及子任务组
- 一个 task_group 并不会限制其 task 都是运行在哪一个 cpu 上
- 一个 task_group 的 load_avg 就是其所在 cpu 的 load_avg 的总和
- 需要 per_cpu 的 cfs_rq 是因为 cfs_rq 是用于管理的
- 需要 per_cpu 的 se 是因为 se 作为挂载使用的
- [x] struct task_group::shares
- `share` is exclusive concept used for task_group, describing share of a task_group in all task_groups
- [ ] calc_group_shares()
- `reweight_entity` : 作用就是将 重新计算一下 load_avg, 因为该 tg 的 weight 发生了变化
第一件事情,当我们试图调整 share 的时候,是不是最终会影响到每一个所有人 task 的 weight ?
- 这样是不是太慢了,甚至那些没有处于就绪队列的 task 的 weight 都需要重新计算
- 但是 vruntime 的计算是靠 除以 weight 来的
- 实际上的策略是,将整个 group 当做一 asdfa 个 se, 当 share 调整之后,只是需要重新调整这个 group 的 weight 的
- 其实所有的 process 都是放到 group 中间的
- weight 不是直接算到每一个 se 上的
- 感觉 share 就是 weight 啊
- group 可能分布于所有的 cpu 上,但是,calc_group_shares 的参数只是一个 se
- 而 cfs_rq 中间选择其最佳的 se 的时候,显然是从当前的 se 中间选择的
- 如果 cpu A, B 中间都有进程,并且 A 中间有 tg 的 weight 为 1000, B 中间为 10, 那么 tg 在 A, B 对应的 se 的 weight 调整显然不同
```plain
tg->weight * grq->load.weight
e->load.weight = ----------------------------- (1)
\Sum grq->load.weight
- 恐怖注释中间的,
tg->weight实际上是tg->shares, 而tg->shares的数值就是普通的 weight
numa balancing
-
https://www.linux-kvm.org/images/7/75/01x07b-NumaAutobalancing.pdf : 算是说的很清楚了吧!
-
task_numa_work
- 忽然想到,奔跑上说的内容,是不是只对于 die 级别的,根本没有考虑 numa 层次
- 如果 load balancing 只是能处理同一个 die 级别的,这不是会导致有的线程永远无法迁移其他的可用的 core 上去 ?
- update_numa_stats : Gather all necessary information to make NUMA balancing placement decisions that are compatible with standard load balancer. This borrows code and logic from
update_sg_lb_statsbut sharing a common implementation is impractical.
struct task_numa_env {
struct task_struct *p;
int src_cpu, src_nid;
int dst_cpu, dst_nid;
struct numa_stats src_stats, dst_stats;
int imbalance_pct;
int dist;
struct task_struct *best_task;
long best_imp;
int best_cpu;
};
- task_numa_fault : 调用者来自于 remote process 的位置,其中
- numa_migrate_preferred
- task_numa_migrate :
- task_numa_find_cpu
- task_numa_compare : 如果 task 迁移到新的 CPU 上去会更加好 ?
- task_numa_find_cpu
- task_numa_migrate :
- numa_migrate_preferred
fair.c 源码分析
- 从 1000 ~ 2700 config_numa_balancing
- 3700 计算 load avg 以及处理 tg 等东西
- 4000 dequeue_entity 各种 entity_tick 之类的
- 5000 作用的位置,处理 bandwidth
- 后面也许都是在处理 cpu attach 的吧
update_cfs_group : shares runable 然后利用 reweight_entity 分析
- pick_next_task_fair
- check_cfs_rq_runtime
- cfs_rq_throttled
- check_cfs_rq_runtime
- pick_next_entity_fair
- put_prev_entity
- set_next_entity
- set_curr_task_fair
- set_next_entity
taks group
- root_task_group 在 sched_init 中间被初始化 ?
// init_tg_cfs_entry 的两个调用者
int alloc_fair_sched_group(struct task_group *tg, struct task_group *parent)
void __init sched_init(void)
void init_tg_cfs_entry(struct task_group *tg, struct cfs_rq *cfs_rq,
struct sched_entity *se, int cpu,
struct sched_entity *parent)
// @todo 找到,缺少加入 task_group 离开 task_group 之类的操作
// 调用的地方太少了
还是 init_tg_cfs_entry 含有一些有意思的东西。
详细内容
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
static inline void update_load_sub(struct load_weight *lw, unsigned long dec)
static inline void update_load_set(struct load_weight *lw, unsigned long w)
// 辅助函数,@todo load_weight 中间 inv_weight 到底如何使用 ?
// 利用load weight 计算 @todo 计算什么来着 ?
static void __update_inv_weight(struct load_weight *lw)
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
// 为 CONFIG_FAIR_GROUP_SCHED 而配置的各种辅助函数
static inline struct rq *rq_of(struct cfs_rq *cfs_rq)
static inline struct task_struct *task_of(struct sched_entity *se)
static inline struct rq *rq_of(struct cfs_rq *cfs_rq)
static inline struct cfs_rq *task_cfs_rq(struct task_struct *p)
static inline struct cfs_rq *cfs_rq_of(struct sched_entity *se)
static inline struct cfs_rq *group_cfs_rq(struct sched_entity *grp)
static inline void list_add_leaf_cfs_rq(struct cfs_rq *cfs_rq)
static inline void list_del_leaf_cfs_rq(struct cfs_rq *cfs_rq)
static inline struct sched_entity *parent_entity(struct sched_entity *se)
static inline void find_matching_se(struct sched_entity **se, struct sched_entity **pse)
// Scheduling class statistics methods:
// 700 line
// 6000 - 10000 用于迁移
// 6296
/*
* select_task_rq_fair: Select target runqueue for the waking task in domains
* that have the 'sd_flag' flag set. In practice, this is SD_BALANCE_WAKE,
* SD_BALANCE_FORK, or SD_BALANCE_EXEC.
*
* Balances load by selecting the idlest CPU in the idlest group, or under
* certain conditions an idle sibling CPU if the domain has SD_WAKE_AFFINE set.
*
* Returns the target CPU number.
*
* preempt must be disabled.
*/
static int select_task_rq_fair(struct task_struct *p, int prev_cpu, int sd_flag, int wake_flags)
// selecting the idlest CPU in the idlest group
// 文章中间提到的 group 以及 domain 的概念来处理
// 6365
/*
* Called immediately before a task is migrated to a new CPU; task_cpu(p) and
* cfs_rq_of(p) references at time of call are still valid and identify the
* previous CPU. The caller guarantees p->pi_lock or task_rq(p)->lock is held.
*/
static void migrate_task_rq_fair(struct task_struct *p, int new_cpu)
// 不知道是做什么的,四个辅助的小函数
static void rq_online_fair(struct rq *rq)
{
update_sysctl();
update_runtime_enabled(rq);
}
static void rq_offline_fair(struct rq *rq)
{
update_sysctl();
/* Ensure any throttled groups are reachable by pick_next_task */
unthrottle_offline_cfs_rqs(rq);
}
static void task_dead_fair(struct task_struct *p)
{
remove_entity_load_avg(&p->se);
}
/*
* sched_class::set_cpus_allowed must do the below, but is not required to
* actually call this function.
*/
void set_cpus_allowed_common(struct task_struct *p, const struct cpumask *new_mask)
{
cpumask_copy(&p->cpus_allowed, new_mask);
p->nr_cpus_allowed = cpumask_weight(new_mask);
}
看看这个
https://utcc.utoronto.ca/~cks/space/blog/linux/LoadAverageWhereFrom
本站所有文章转发 CSDN 将按侵权追究法律责任,其它情况随意。